
(revisado en mayo 2025)
Al acabar la entrada anterior de la serie la Biografía de la Vida habíamos dejado a unas células eucariotas que habían aprendido una habilidad que con el tiempo les va a abrir un mundo de desarrollo y complejidad: la reproducción sexuada. Hoy vamos a darnos un paseo por un campo teórico de la Vida. No hablaremos de organismos en particular, ni de habitantes de la biosfera, sino de algo compartido por todos, desde las bacterias a los elefantes africanos, pasando por las libélulas o las estrellas de mar: hablaremos de la genética.
La genética
No entenderíamos el proceso de la herencia si no profundizáramos antes en los mecanismos básicos de la genética: qué es un gen, como actúa el ADN, cuál es el diccionario universal para interpretar a los genes, etc…
El genotipo es la totalidad de la información genética que posee un organismo, que conjuntamente con el medio ambiente determina la forma de ser tanto física como de conducta de un individuo. Ya sabemos que no sólo se encuentra en los núcleos celulares de las eucariotas o en el nucleoide de las procariotas, sino también en otros orgánulos celulares como los ribosomas, las mitocondrias o los cloroplastos. Es un compendio de la historia evolutiva de cada individuo. Hay una parte de él que tiene una antigüedad de más de 3.500 millones de años, que le ha sido transmitida a través de millones de antecesores, y otra parte nueva, que es exclusiva de cada uno de ellos.
La información del genotipo se esconde en el ADN, y más concretamente en los genes, y se transmite mediante la herencia a la descendencia.
Pero ¿qué son los genes?
El ADN es el Ácido DesoxirriboNucleico. Es el tipo de molécula más compleja que se conoce, formada por una larga secuencia de nucleótidos, que contiene la información necesaria para poder controlar el metabolismo y la herencia en un ser vivo. El ADN es, en definitiva, el “sancta sanctorum” donde reside su información genética.

El nucleótido correspondiente a la base nitrogenada Adenina
Los nucleótidos son moléculas orgánicas formadas por la unión de un azúcar de cinco carbonos, una base nitrogenada y un grupo fosfato. En el ADN el azúcar es la desoxirribosa y las bases nitrogenadas son de cuatro tipos: adenina (A), guanina (G), citosina (C) y timina (T). Las cadenas del ARN son ligeramente diferentes ya que cambian el azúcar, que ahora es la ribosa, y la timina que pasa a uracilo (U). Tanto en el ADN como en el ARN los nucleótidos se unen entre sí mediante sus grupos fosfato.
Los nucleótidos son capaces de emparejarse mediante enlaces por puentes de hidrógeno[1], siempre de la misma forma y siempre Adenina-Citosina y Guanina-Timina. Y no puede ser de otra manera por estrictas razones físicas de la configuración geométrica de sus moléculas. Las parejas de nucleótidos –parejas de bases- así conformadas se unen ahora entre sí a través de sus grupos fosfato. En la figura de más abajo se pueden ver ambos tipos de enlaces, los puentes de hidrógeno como una mera unión por aproximación de cargas negativas y positivas y el segundo como un enlace fosfodiéster[2] En esta reacción se libera una molécula de agua y se forma un dinucleótido. en donde sí se comparten orbitales electrónicos entre moléculas.
Esta sencilla estructura se repite formando un largo polímero que se “retuerce” adoptando la forma de una doble cadena helicoidal que mide de 2,2 a 2,6 nanómetros (un nanómetro equivale a 10-9metros) de ancho, mientras que un nucleótido tiene una longitud de 0,33 nanómetros. Aunque cada unidad individual de la hélice es muy pequeña, los polímeros de ADN pueden ser moléculas enormes que contienen millones de nucleótidos. Por ejemplo, el cromosoma humano más largo, el cromosoma número 1, tiene aproximadamente 250 millones de pares de bases. También se sabe que en algunos casos el ADN puede adoptar una configuración de cuatro hebras: “cuádruple hélice”.
Esta doble hélice, con la ayuda de ciertas proteínas llamadas histonas, se enmadeja y se empaqueta hasta formar la cromatina en la situación habitual de la célula o como cromosomas cuando está en proceso de mitosis. La cromatina adopta una forma de fibras enrolladas que pueden variar en su grado de compactación. En su estado más laxo (eucromatina), se ve como una fibra delgada y dispersa, lo que permite el acceso al ADN para la transcripción. En su estado más compacto (heterocromatina), se enrolla de forma más densa y apretada, haciendo que el ADN sea menos accesible. Las dos formas de cromatina no son excluyentes, sino que coexisten dentro del núcleo de una misma célula.
Los biólogos James Watson y Francis Crick fueron los que en 1953 propusieron la estructura helicoidal para esta molécula, por lo que recibieron el premio Nobel de Medicina en 1962. A decir verdad ellos culminaron el trabajo de muchos científicos anteriores, desde el español y también premio Nobel Severo Ochoa hasta la británica Rosalind Franklin que les dejó la solución en bandeja.

La cadena helicoidal del ADN y detalle de los dos tipos de enlaces que le dan cohesión
Un gen está constituido por una determinada sucesión de nucleótidos de la molécula de ADN. Esta secuencia de nucleótidos puede ser, por ejemplo, la AATGGCCGTTAG, y su pareja “cremallera” de la hélice del ADN, la TTACCGGCAATC. La disposición ordenada de las cuatro bases constituye una información “digital” necesaria para la síntesis de las proteínas, aunque también informa sobre diversos tipos de ARN, ya sea mensajero, ribosómico o de transferencia. Por este motivo la cantidad de información se suele dar en pares de bases.
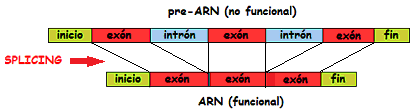
No obstante, no toda la secuencia de pares de bases de la cadena es útil a efectos de genera una proteína ya que unas partes codifican información (los exones) y otras no (los intrones). Hasta hace poco no se sabía muy bien el porqué de la ausencia de este tipo de funcionalidad de los intrones, aunque al hablar de la aparición del núcleo celular[3] ya planteamos una teoría de su existencia y función. Pero los conocimientos de la genética están evolucionado enormemente en los últimos años. Ahora sabemos que los intrones no son tan inútiles como se postulaba pues, aunque no codifican proteínas directamente, son fundamentales para la regulación, diversidad y evolución genética. Lejos de ser inútiles, permiten que los genes sean más versátiles y adaptables. Así pues, un gen consistiría en una serie de exones entre los que se intercalan uno o varios intrones no codificantes. Hoy sabemos que cerca del 30% del ADN de las eucariotas está formado por intrones, mientras que las procariotas carecen de ellos.
Pero volvamos al genoma. La longitud del ADN es diferente para cada especie, de forma que incluso especies parecidas tienen cantidades de ADN muy diferentes entre sí, como se puede ver en la figura siguiente. El del hombre tiene unos 3.200 millones de pares, es decir, incorpora una información equivalente a 60.000 entradas como ésta que estás leyendo si cada par equivaliera a una letra, en los que se encuentra escrito todo el historial evolutivo de nuestra especie.
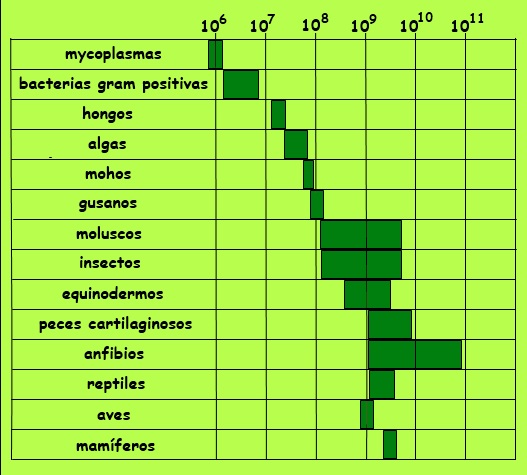
Longitud del genoma en pares de bases
Ahora bien, lo realmente significativo es el número de genes diferentes, ya que ello define en principio el potencial químico del ADN. El arroz tiene unos 40.000 genes, la mosca 13.900 y el hombre unos 21.000. Produce sorpresa la comparación entre el arroz y el hombre, por ejemplo, aunque se cree que la regulación de los genes humanos es más rica, compleja y eficiente. Y en ello tiene mucho que ver el ADN no codificante de proteínas y otros factores de regulación biológica en las células. El tamaño del genoma del Trillium, planta de la familia de los lirios, es más de 20 veces el de la planta del guisante y 30 veces el de los humanos. Algunas amebas unicelulares tienen un genoma 200 veces el tamaño del genoma humano. Estas incongruencias, que se conoce como la paradoja del valor C, pueden explicarse por la existencia del ADN no codificante, del que hablaremos unos pocos párrafos más adelante.
En la figura anterior hemos visto cómo a medida que se va avanzando en la escala evolutiva, parece como si el genoma tendiera generalmente a hacerse mayor. Aunque no es una regla perfecta entre familias sí lo es entre las especies dentro de una misma familia. Pero ¿cómo sucedió esto? ¿Cómo pudo ser que las antiguos ácidos nucleicos alargaran sus cadenas?
En otra entrada anterior,[4] donde hablábamos de la “teoría del hidrógeno” de Martin y Müller, ya comentamos la aportación de las mitocondrias al ADN de sus hospedadoras. Ésta fue una vía, aunque también hay otras teorías.
Como la que explicaba ya en 1985 el biólogo Thomas Cavalier-Smith partiendo de la realidad apuntada un par de párrafos antes: un organismo más evolucionado desarrolla un metabolismo más complejo, que simplemente requiere un mayor espacio donde llevar a cabo su química, lo que al final supone una célula mayor. Como hay una correlación entre la actuación del ARN ribosómico en el citoplasma celular -en donde se fabrican las proteínas- y el ARN que transcribe el ADN en el núcleo, es preciso un núcleo más grande en una célula más grande. El proceso de mitosis (hablaremos de este tipo de división celular un poco más abajo) de un núcleo más grande, con sus estructuras de microtúbulos, centriolos y husos, pudo requerir cromosomas más largos. Esto no suponía un mayor número de genes, ya que se necesitaban los que se necesitaban. Así que el ADN creció duplicando y duplicando largas porciones de su cadena molecular. Es un hecho que casi la mitad del ADN de las células eucariotas consiste en secuencias de nucleótidos que se repiten centenares o miles de veces.
Pudo ser consecuencia de este desmedido crecimiento el que en las células eucariotas exista un exceso de ADN que no expresa directamente proteínas, el llamado ADN no codificante, del que sólo ahora empieza a conocerse algunas de sus funciones. En la especie humana sólo del 1 al 2 % del ADN son genes codificantes. En las células procariotas, sin embargo, se usa casi todo el ADN.
¿ADN basura?
Hasta hace poco al ADN no codificante se le llamaba ADN “basura”, ya que se suponía que no desarrollaba ninguna función siendo el resultado de antiguas duplicaciones en la cadena del ADN y restos de genes desactivados. Sin embargo, en los últimos años está ganando fuerza la teoría de que todo ese material genético no codificante sí debe tener alguna funcionalidad, como pudiera ser el dotar al ADN de su forma y estabilidad fisicoquímica, o bien ejercer una función reguladora controlando el nivel de expresión génica, entre otras. En 2003 se inició el proyecto ENCODE (ENCyclopedia Of DNA Elements)[5] que pretendía constituirse en una completa enciclopedia del ADN. Los estudios desarrollados han llegado a conclusiones que echan por tierra el concepto del ADN basura al concluir que por lo menos el 80% de la cadena de ADN considerada como “no codificante” tiene actividad biológica y hace que el ADN codificante se exprese, se active o se silencie. Es como si fuese un gran panel de control con millones de interruptores, que según se posicionen alteran el resultado final de la expresión de los genes “activos”. Es decir, que estos no funcionan de forma individual bajo el lema “un gen-una proteína”, sino que todo quedaría en manos de redes extensas de interacción entre grupos de genes.
De todas formas no debería extrañarnos la existencia del ADN “basura”, ya que debe ser consecuencia casi espontánea de la evolución. El comportamiento general de ésta no es que se corresponda ciertamente con algo ordenado, perfectamente diseñado en todos sus detalles y eficiente; al contrario, se comporta casi como una gran chapuza de recorta y pega. Los fenómenos de degeneración de algún gen y consiguiente pérdida de su funcionalidad, así como la inmersión de virus en las cadenas del ADN es una realidad que se ha venido produciendo a lo largo de toda nuestra historia genética. Y el hecho de que todas estas “imperfecciones” no hayan sido lavadas se debe en parte a que no son perjudiciales, no hacen daño en el funcionamiento metabólico, y tocarlas sin necesidad supone un riesgo de desequilibrio. Y en otra gran parte a que es pieza de una estrategia de diversidad, agilidad y duplicidades de soluciones: el “desorden” en la regulación y expresión génica no es un error sino un recurso evolutivo clave para la versatilidad, rapidez de respuesta y complejidad funcional en organismos superiores.
Porque la “indiferencia” de la evolución también tiene ventajas. A mayor longitud (¿mayor porcentaje de ADN basura?) mayores son las oportunidades. Cualquier modificación “indiferente” en la cadena de nucleótidos que conforman el ADN entra a formar parte en el acervo genético con futuribles. En el entorno ambiental del momento de la alteración la mutación se manifiesta como irrelevante. Pero en un entorno cambiante puede ser probable que en un futuro las nuevas condiciones medio ambientales den una oportunidad a un gen hace mucho tiempo mutado, incluidos los de la cadena de ADN no codificante, un gen que lleva consigo lo que en las nuevas circunstancias se manifiesta como una ventaja evolutiva. De esta manera podemos generalizar que a mayor longitud del ADN “basura” mayor es el número de mutaciones “indiferentes” que alberga y a la vez mayor es el número de oportunidades durmientes a la espera de activarse cuando el medio reconozca su ventaja. Quién sabe si esta pueda ser la defensa futura frente a enfermedades hoy en día incurables ¿Por qué hay individuos que no desarrollan una enfermedad aunque estén contagiados con el patógeno que la produce? Tengo que reconocer que esto último es una mera especulación mía pero bien pudiera ser.
La expresión génica es algo endiabladamente complejo
En los organismos eucariotas las secuencias codificadoras de exones dentro de un gen normalmente no son continuas, sino que[6] están interrumpidas por las secuencias no codificadoras de intrones. Cuanto más evolucionada es una especie más cantidad de intrones tiene. Cuando se ha de codificar una proteína o un ARN, los intrones deben desacoplarse, y sabemos que lo hacen dentro del núcleo, para que la cadena de exones se reúna después antes de empezar su trabajo. Todo ello constituye lo que llamamos splicing, el empalme alternativo. Es, efectivamente, una fuente de posibles errores y cambios, aunque también es una fuente de versatilidad.
Transcripción de la secuencia codificadora del gen del ADN al ARN mensajero
Durante el proceso de splicing pueden producirse distintas alternativas de combinación de los exones -splicing alternativo-, de tal manera que a partir del mismo pre-ARN mensajero pueden obtenerse diferentes proteínas (ver figura siguiente). De esta forma, la cantidad y variabilidad de proteínas posibles aumenta considerablemente sin que lo tenga que hacer el número de genes. De hecho, se calcula que en el ser humano cerca del 50% de transcritos primarios son susceptibles de sufrir splicing alternativo. Llegando al caso extremo hoy por hoy conocido, el del gen Dscam de Drosophila, que presenta 38.000 variantes de splicing, y por tanto de proteínas subproducto, un número mayor que el del total de sus genes.

Esquema del funcionamiento del splicing alternativo, mediante el cual un mismo gen puede expresar diversas proteínas distintas
Lo anterior refuerza las conclusiones del ENCODE y pone patas arriba la idea, casi ley, de que a cada gen le corresponde una proteína. Las particularidades del proceso de expresión de los genes que exponemos a continuación ayudarán a reforzar el entendimiento del concepto anterior.
Tanto en procariotas como en eucariotas, al comienzo de la secuencia codificante de un gen aparece una sección de ADN denominada promotor, que es capaz de activar o desactivar la transcripción del gen, proceso que suele estar mediado por proteínas específicas llamadas factores de transcripción. Incluso los propios intrones participantes en el splicing pueden realizar estas funciones de regulación. Este proceso es casi como poner una llave en la cerradura y abrir la puerta (aunque la realidad no es tan mecánica).
Pero hay otra modalidad de expresión de genes por la que se abre la puerta con un mando a distancia. Es otro tipo de mecanismo de control que está constituido por los interruptores genéticos, que son estructuras distintas a los promotores y que están constituidos por dos elementos: los potenciadores y los factores de transcripción. Un potenciador, o intensificador, es un fragmento de la propia cadena de ADN no codificante, que puede encontrarse cerca del gen o alejado de él -incluso a miles de nucleótidos de distancia- y que presenta unos lugares específicos de unión física para los factores de transcripción. Cuando los factores de transcripción se unen al potenciador, el gen se «activa», produciéndose la transcripción. Los potenciadores son como un cerrojo wifi en donde tiene que entrar una llave determinada para que la trascripción tenga lugar.
Lo que parece tan sencillo tiene una segunda derivada decisiva para el organismo. Los factores de transcripción no dejan de ser unas proteínas más que requieren en su “fabricación” la acción de más genes. Con lo cual deberemos plantearnos la siguiente pregunta ¿quién regula a su vez los factores de transcripción? No debe resultar sorprendente el que al perseguir fisiológicamente este tema lleguemos a causas que encontramos, entre otros, en la situación química del medio citoplasmático, o en la influencia de las células vecinas, o en los niveles hormonales que permean todo el cuerpo, o incluso ¡lo que está sucediendo fuera de él, en su exterior![7] es decir, en el ambiente donde se encuentra inmersa la célula: los genes no completan su sentido si nos olvidamos del contexto del ambiente en donde se expresan. Realmente se observa que cuanto más complejo genómicamente es un organismo, mayor es el porcentaje del genoma dedicado a la regulación génica a cargo del ambiente. Lo que nos conecta con lo que habíamos dicho más arriba acerca de la capacidad codificadora de genes que encontramos en el ADN “basura”.
Pero los procesos reguladores se nos complican más al saber de la “plasticidad” de las proteínas y sus tendencias “promiscuas”. Las proteínas no siempre son rígidas ni exclusivas: pueden cambiar de forma (plasticidad) lo que les facilita el tener múltiples y evanescentes interacciones (promiscuidad) según las circunstancias, lo que les da versatilidad funcional y un papel clave en la complejidad biológica. La plasticidad les permite adaptarse a diferentes entornos o condiciones celulares, a interactuar con múltiples moléculas o a cambiar su actividad según el contexto; mientras que la promiscuidad les es útil para ahorrar recursos celulares, favorecer la evolución de nuevas funciones o participar en redes de señalización complejas[8]. A diferencia de las proteínas rígidas que tienen una única forma funcional, muchas proteínas pueden “moldearse” dinámicamente. Esto es especialmente importante en procesos como la señalización celular (la “conversación” entre células), el reconocimiento molecular (la “conversación” entre moléculas), la catálisis enzimática o la respuesta al estrés. Esta flexibilidad les permite cumplir diversas funciones sin necesidad de cambiar su secuencia de aminoácidos. Es una propiedad crucial para la adaptación y la regulación biológica. Un ejemplo lo tenemos en la proteína p53 supresora de tumores. Su estructura es flexible y se reorganiza para interactuar con diferentes tipos de ADN, proteínas reguladoras y otros cofactores. Según el tipo de daño celular o señal externa, p53 adopta distintas conformaciones que determinan si la célula debe detenerse, repararse o entrar en apoptosis (muerte celular programada).
Algo semejante lo encontramos en la promiscuidad de las proteínas, que es la versátil capacidad funcional que tienen algunas de ellas -especialmente enzimas y proteínas reguladoras- para interactuar con múltiples socios moleculares o catalizar más de una reacción diferente. Esta promiscuidad no es un error del sistema sino una característica evolutivamente ventajosa, ya que permite eficiencia, reutilización funcional y mayor adaptabilidad en entornos cambiantes. Encontramos un ejemplo en citocromo P450, una familia altamente promiscua de enzimas presente en casi todos los organismos. Son capaces de reconocer y metabolizar una gran variedad de sustratos con estructuras químicas muy distintas. lo que se revela fundamental en el hígado humano, donde permite que el cuerpo procese y elimine múltiples sustancias sin necesidad de tener una enzima distinta para cada una.
Lo ampliamos. En el interior de la célula muchas proteínas no actúan de forma aislada sino que tienden a agruparse en conglomerados temporales que se forman y disuelven según las necesidades funcionales del momento. A diferencia de los complejos proteicos estables que tienen una estructura fija y función constante, estos conglomerados, también llamados condensados biomoleculares, son dinámicos y reversibles. Se comportan como gotas líquidas sin membrana, concentrando proteínas, ARN y otras moléculas específicas en espacios reducidos dentro del citoplasma o del núcleo. Los componentes de estos conglomerados entran y salen continuamente de la gota, lo que permite una renovación constante y una gran flexibilidad funcional. Esta dinamicidad es esencial para que la célula pueda adaptarse rápidamente a cambios internos o señales externas. Por ejemplo, en situaciones de estrés se forman ciertos condensados para secuestrar proteínas o ARN y protegerlos hasta que las condiciones vuelvan a ser favorables. Y en particular, en el núcleo se generan algún tipo de esos conglomerados que regulan la expresión génica, ensamblándose cerca de determinados genes para activar o silenciar su transcripción, y luego desapareciendo cuando ya no se necesitan. ¿Cómo lo consiguen? es materia aun no muy conocida.
Para completar la nómina de “perturbaciones” genéticas hay que comentar también las que introduce la cromatina. La plasticidad de la cromatina -su capacidad de cambiar entre estados más abiertos (eucromatina) o compactos (heterocromatina)- es clave para la regulación de la expresión génica, porque determina qué regiones del ADN están accesibles para ser leídas y transcritas. Cuando la cromatina se relaja, los factores de transcripción y la maquinaria celular pueden acceder al ADN, lo que favorece la activación de genes. En cambio, cuando se condensa, el ADN queda “oculto” y los genes en esa región suelen estar silenciados. Pero es que además se presta a modificaciones puntuales, esporádicas y temporales gracias a las que la expresión génica se adapta a diferentes funciones, tiempos y entornos. Por ejemplo, la reconfigura de la cromatina abre en la célula regiones de genes específicos necesarios para su nueva función o cierra otras regiones que ya no necesita, es decir, que células con el mismo ADN puedan expresar genes distintos según su identidad.
Lo descrito hasta ahora nos permite entender cómo muchos genes tienen expresiones de lo más variopintas y nada específicas, provocadas por iniciadores y causas muy diversas. A la casuística de tener más de un potenciador y por lo tanto más de un «interruptor» que en buena medida depende del ambiente, se le añade la aleatoria diversidad que permite el splicing, o el difuso (por lo aun desconocido para nosotros) comportamiento de las especiales “habilidades” de las proteínas celulares o la versatilidad estructural de la cromatina… entre otras mil cosas sabidas y aun no entendidas. Esto permite que un único gen juegue su papel en distintos momentos, cuándo, y lugares del desarrollo del organismo, dónde, existiendo un control independiente para cada uno de ellos. Es como si los genes fueran una especie de subrutinas estándares dentro del software del ADN,[9] a las que se acude cuando un programa más general requiere de su intervención. El ADN se comporta más como una caja de herramientas (genes) que como un ente con algún tipo de entes con una agencia precisa.
También sabemos que la regulación génica no está exclusivamente en manos de las proteínas sino también en las de cadenas de ARN regulador no codificante, expresadas por los propios genes. La regulación génica por ARN’s largos y cortos no codificantes es un mecanismo esencial que complementa y afina la expresión de los genes más allá del control directo del ADN. Y aunque no codifican proteínas, estos ARN cumplen funciones reguladoras potentes, actuando a distintos niveles del proceso génico. Los ARN de cadena corta no codificantes Incluyen principalmente los microARN (miARN) y los siARN (ARN pequeños de interferencia). Son moléculas de unos 20-25 nucleótidos que regulan la expresión post-transcripcionalmente, es decir, después de que el ARN mensajero (ARNm) ha sido producido. Mientras que los de cadena larga no codificantes, con más de 200 nucleótidos, ejercen una acción más diversa y menos comprendida que la de los ARN cortos. Pueden actuar en el núcleo o en el citoplasma y regulan la expresión génica de múltiples maneras: Modulando la estructura de la cromatina al reclutar proteínas que activan o silencian genes; interfiriendo con la transcripción al unirse al ADN o al ARN en formación; o secuestrando proteínas reguladoras o miARN al actuar como “esponjas” moleculares.
La complejidad que hemos intentado poner de manifiesto en los párrafos anteriores remacha lo erróneo de la visión tradicional de “un gen: una proteína: una función”. La regulación fisiológica es algo más, mucho más complejo. Parece como si la simple línea causal expuesta fuera mucho más rica, como si en cada nivel de complejidad biológico emergiera su propia dinámica causal autónoma que no precisara de la de niveles “inferiores” (o superiores), pero que convivieran a la vez sin ser excluyentes. Algo así como pasa en el mundo de la física en la que siendo el mismo dominio, la causalidad cuántica no tiene nada que ver con la causalidad química y esta con la biológica, aunque todas se necesiten. La emergencia de la causalidad en la regulación biológica surge de interacciones dinámicas, distribuidas y a múltiples niveles. En lugar de que un solo elemento dicte el resultado, es la red de relaciones entre genes, proteínas, metabolitos, señales y estructuras celulares la que genera comportamientos regulados y coherentes. Esta causalidad emergente no puede predecirse completamente a partir de las partes individuales, porque el todo tiene propiedades que van más allá de la suma de sus componentes. Por ejemplo, la diferenciación celular o la respuesta inmune no se explican únicamente por la presencia de ciertos genes, sino por cómo estos genes se activan o silencian en contextos específicos, influenciados por el entorno, la historia celular y otras señales. Vemos entonces como la biología moderna se está adentrando en una senda que deja atrás la idea de que la causalidad biológica es simple y jerárquica, al percatarse y reconocer que es compleja, contextual y emergente.
Como vemos, la expresión génica, y sus derivados aguas abajo, está configurado como un proceso complejo y sofisticado que permite que los organismos celulares alcancen fenotipos muy desarrollados. Pero no olvidemos sus inicios, que se remonta quizás en la simbiosis que creó las mitocondrias. Y con ellas los transposones, los intrones, con su capacidad de autorrecorte. La célula reaccionó de muchas maneras para aplacar el problema, entre otras aplicando el splicing aprendido de los transposones a los trozos en que quedaban divididos sus genes, proceso por el que no solamente limpiaba y reconstruía la cadena completa de un gen inicial, sino que en el proceso se producirían además errores que formarían nuevos genes, los cuales a su vez expresarían nuevas proteínas. Inicialmente los errores podrían tener poco efecto, pero con el tiempo la nueva proteína podría asumir una función novedosa. Es sorprendente cómo de forma fortuita la deriva de las eucariotas para combatir a los intrones hizo a sus genes más versátiles y más capaces de apoyar nuevas estrategias evolutivas.
Hay que avanzar. Hasta aquí hemos definido qué es el genotipo, cómo son los genes y algunos mecanismos de activación del proceso de transcripción o de expresión proteínica. Pasemos a ver cuáles son los códigos secretos que traducen la información inmersa en las secuencias de nucleótidos de los genes de forma que se den las instrucciones precisas para sintetizar una proteína.
El código genético
Todo funciona gracias a un manual de contraseñas llamado código genético. Por su sencillez resulta brillante y elegante. Por su universalidad resulta abrumador: todos los seres vivos utilizan este manual de reglas secretas, desde la más humilde bacteria a una cactácea, desde un hongo al mamífero más complejo, todos utilizan el mismo manual de traducción. Este código es muy ancestral y prácticamente no ha sufrido cambios, lo que indica un origen único y universal. Realmente es una prueba casi concluyente del origen común de los individuos vivos, de la existencia de un ancestro común. Fuera cual fuera el detonador del origen de la Vida.
Todo está basado en los codones o grupos repetitivos de tres nucleótidos seguidos, y en un mismo orden, en la cadena de un gen. Cada codón transcribe la orden de sintetizar uno de los 20 aminoácidos existentes en los organismos vivos.
Sabemos que cuatro son los nucleótidos formantes del ADN, adenina (A), timina (T), guanina (G) y citosina (C), y además el uracilo (U), que en el ARN sustituye a la timina. Si los agrupamos de tres en tres, con repetición, tendremos 64 (43) posibles ternas, 64 posibles codones. Dado que solamente se deben sintetizar 20 aminoácidos está claro que a un mismo aminoácido le puede corresponder más de un codón, pero nunca un mismo codón expresará más de un único aminoácido. A eso se le llama una relación “degenerada”. Si no fuera así, la probabilidad de error en las traducciones que se realizan en los ribosomas sería muy elevada.
Hay tres ternas que codifican la orden de parada en el proceso de síntesis de la proteína. Y hay un codón, el AUG, que se corresponde con el aminoácido metionina, que codifica el inicio. Todos los procesos de traducción de una secuencia de nucleótidos en otra de aminoácidos comienzan por el reconocimiento del codón de iniciación. Así, todas las proteínas comenzaran por este aminoácido, AUG. De esta manera se asegura una correcta lectura de la secuencia de ternas de nucleótidos. El proceso termina cuando se llega a uno de los codones de parada.

Código genético: en el centro los aminoácidos que expresan cada terna de nucleótidos
Todo el proceso de síntesis de una proteína viene dirigido por un ARN mensajero (ARNm) y requiere una gran complejidad. Hay que recordar que el mensajero se crea por copia de un tramo de una de las cadenas de la hélice del ADN, siguiendo la regla de los pares homólogos de nucleótidos, G-C y A-U. Es lo que llamamos la transcripción. Una vez formado el ARN mensajero llega a los ribosomas, en donde se lleva a cabo físicamente la traducción, construyéndose así las proteínas según la secuencia de aminoácidos indicada por el mensajero y gracias a la aportación de los adecuados materiales –aminoácidos- que realiza un ARN de transferencia (ARNt). El ribosoma está constituido por otro tipo de ARN, el ribosómico (ARNr), unido a una serie de proteínas específicas. Hablaremos de este proceso unos párrafos más abajo.
Hay diversas teorías sobre la aparición de este código mágico, que inicialmente debió ser muy ambiguo, aunque ninguna concluyente. Realmente su origen es una más de las piezas desconocidas del mundo prebiótico y de la aparición de la Vida.
Una de las teorías más reconocidas es la que explica el origen de cada uno de los tres nucleótidos del codón. La primera letra estaría relacionada con el precursor del aminoácido concreto que sintetiza. La segunda letra del codón estaría relacionada con la hidrofobia o filia del aminoácido. La tercera letra está “degenerada” y no implicaría en principio ninguna información concreta. Pero dos posiciones, las dos primeras letras, a ocupar por cuatro letras –cuatro nucleótidos- da 16 posibilidades de información, lo que proporciona un potencial para expresar 15 aminoácidos más un codón de parada. Inicialmente, en los albores de la vida metabólica, sólo existirían 15 aminoácidos, que “compitieron” entre ellos por una tercera letra, como así parece que es en la realidad para los 15 aminoácidos más comunes. Los otros cinco aminoácidos posteriores -hasta los 20- tienen menos variación en la tercera posición, como el triptófano que sólo es secuenciado por un codón acabado en G. Esta tercera posición debió imponerse a través de mecanismos de selección natural, ya que se ha demostrado matemáticamente que la actual estructura del código genético es la que con mayor efectividad evita las posibles mutaciones y sus perjuicios: con ello se disminuirían, por un lado, los problemas de fidelidad en la replicación de la cadena ADN, al haberse diseñado codones con funciones similares, y por otro, los problemas de errores durante la traducción en el ribosoma, al interpretar varios codones distintos a aminoácidos semejantes. La distribución de la tercera letra tras las parejas iniciales fue como fabricar diversos comodines para una misma jugada, lo que habría dificultado el que sucedieran los errores.
¿Cuál es el proceso que desde la información codificada en la doble hélice del ADN nos conduce hasta el abanico de funciones dirigidas por moléculas de proteínas?
Proceso general desde la información genética a la síntesis de una proteína. Aquí se observa cómo la membrana del núcleo separa físicamente la labor de los intrones de la síntesis de proteínas
En líneas generales, la información que contiene el ADN en sus secuencias de nucleótidos se transcribe a un ARN mensajero de acuerdo al código de emparejamientos. Para ello una enzima ARN-polimerasa crea algo semejante a una burbuja que aísla la porción de ADN que se va a duplicar y separa sus hélices. En este espacio se va a generar el ARNm por copia homóloga de una de las cadenas del ADN abierto. Si el nucleótido del ADN es la Adenina, el ARNm que se está montando como una cremallera incorporará en esta posición un Uracilo. Si es una Guanina el diente del ARN será una Citosina. Y así según los posibles emparejamientos.
El ARNm así formado se le conoce como “pre ARN” ya que hay que procesarlo y limpiarlo de intrones para dejarlo sólo con los exones, según un proceso explicado un poco más arriba. El ARNm resultante sale del núcleo y se dirige al ribosoma para el siguiente paso: la traducción.
La traducción (ver el sentido de las flechas rosas de la figura siguiente) se realiza sobre el entramado de moléculas de ARNr ribosómico y proteínas que constituyen la estructura del ribosoma. El ARNm mensajero lleva las órdenes que son interpretadas por diversos ARN de transferencia, que, como disciplinados trabajadores, leen la instrucción de un codón y capturan el correspondiente aminoácido que incorporan a la cadena de la proteína que están fabricando.

Proceso de traducción en un ribosoma (Wikimedia, dominio público)
Y con esta bella imagen finalizamos por hoy. En la próxima entrada acabaremos el tema de la genética intentando explicar, por un lado, cómo pudo gestarse todo el juego de copias y replicaciones que hoy hemos conocido, y, por otro, los misterios de la división celular y la transmisión de la carga genética. Hasta pronto.
- La molécula de agua es ligeramente dipolar ya que los protones del núcleo del oxígeno “atraen” al conjunto de los electrones de la molécula, dejándola como un imán. Esta bipolaridad es la que le permite constituir enlaces por puente de hidrógeno con otras moléculas también polares. [↩]
- Un enlace fosfodiéster es un tipo de enlace químico covalente que se produce entre un grupo hidroxilo (OH-) en el carbono 3′ y un grupo fosfato (PO43− ) en el carbono 5′ del nucleótido entrante, formándose así un doble enlace éster. [↩]
- En la entrad número 11 de esta serie, “Aparecen las células eucariotas”. [↩]
- De nuevo se trata de la entrad número 11 de esta serie, “Aparecen las células eucariotas”. [↩]
- Para los que tengáis más curiosidad podéis bucear por la web del proyecto ENCODE enlazando aquí o aquí. [↩]
- Como ya sabemos de la entrada número 11 de esta serie. [↩]
- Como nos comenta el neuroendocrinólogo estadounidense Robert Sapolsky en su interesante libro “Compórtate“, pag. 340: “Una hembra huele a su recién nacido… las moléculas olorosas que salen del bebé se unen a receptores situados en su nariz. Los receptores se activan y (muchos pasos después en el hipotálamo) se activa un factor de transcripción, conduciendo así la producción de más oxitocina… que provoca la bajada de la leche.“ [↩]
- Para profundizar más en este último tema recomiendo el revelador libro “How life works” de Philip Ball [↩]
- Los informáticos conocen bien estas rutinas generales, como pueden ser la validación de una fecha, la ordenación de una lista, el cálculo de un dígito de control, etc. [↩]

The La Biografía de la Vida 13. La genética by , unless otherwise expressly stated, is licensed under a Creative Commons Attribution-Noncommercial-No Derivative Works 2.5 Spain License.


{kind=link}
{ 11 } Comentarios
Buen artículo!! Lo leeré con más calma este finde, con más tiempo. Te hago unos apuntillos de mejora: los no químicos te agradecerán una imagencilla para ilustrar los puentes de hidrógeno A-T y C-G.
Luego… en el código genético echo de menos una mencioncita a D. Severo Ochoa!! Para un científico español ilustre que tenemos junto a D. Santiago… al menos démosle lustre.
Saludos!!
Hola Gencianal. Atiendo a tus comentarios. Sin lugar a dudas Severo Ochoa merece un puesto de honor.
Graciñas! Es uno de mis “ídolos”. Seré un bicho raro por fijarme en estos personajes y al mismo tiempo pasar olímpicamente de CR7 y similares…
Muy interesante, un anexo estupendo para la serie. Enhorabuena por hacer claro algo tan complejo, aunque el nivel sigue siendo bastante alto, supongo que tendre que leermelo con mas cuidado otra vez. Lo mejor es que aprovecho para investigar mas cosas, asi que termonio el articulo y me pego un buen rato buceando por la wikipedia y de mas.
Bueno, hay una cosa que no me queda clara:
“Esto último no sólo es el resultado de la “indiferencia”, sino que también podría ser así por sus ventajas: a más ADN “basura”, menores serán las mutaciones que afecten al ADN “activo”, de forma que la mayor parte de las mutaciones genéticas que experimentan nuestro ADN se producen de forma inocua en sus segmentos basura. Así que ahí se quedan, generación tras generación.”
Bueno, no es que no me quede clara, es que no se concuerda con lo que creo saber, asi que necesito que me desasnen un poco mas. A mi entender la probabilidad de una mutacion en el ADN tendria que estar proporcionado con el numero de enlaces total de la cadena, esto haria que al ser mas larga por tener mas ADN “basura” se produjeran mas mutaciones, no protegiendo en absoluto el ADN “activo”.
@Gencianal, yo me fijo en tipos como Ochoa y tambien en tipos como CR7 y similares, lo que sobra es tiempo para interesarse por todo. Lamentablemente, no eres para nada un bicho raro si te dedicas a diferenciarte de los demas por que grupo de idolos tienes, eso lo hace casi todo el mundo.
Hola Sergio B. Es lo que me gusta de los comentarios, que me ayudan a reflexionar. Tienes razón en tu razonamiento acerca de que la longitud del cromosoma no debería influir en una mayor o menor tasa de mutaciones en los genes que llamaríamos activos o que expresan alguna proteína o son agentes iniciadores de estas expresiones. Y es verdad que tal como lo he escrito induce a confusión. Las mutaciones normalmente se producen por errores en el proceso de transcripción cuando se duplica el ADN, se pierde o gana un nucleótido, se duplican trozos de la cadena, se le da la vuelta, se cambian de sitio… y también se producen mutaciones por la acción de agentes externos como pueden ser agentes químicos, radiaciones,… o incluso virus que tras incrustarse se desactivan, baile de transposones,… Tengo claro que en la primera casuística la longitud del ADN basura no va a disminuir el número de mutaciones que se vayan a producir pero en el segundo caso creo que sí va a influir por la simple razón de que cuanto mayor es el objetivo más se reparten las dianas. Una vez más tengo que repetir que no soy un experto en el tema pero cuando escribí el párrafo que comentamos, cuya idea me vino a través de alguna de mis lecturas, lo interpretaba de acuerdo a lo que he escrito más arriba: la longitud sí puede ser una defensa secundaria frente a ataques externos. De todas formas me gustaría tener un rebote de comentario por parte tuya para estar seguro de que así se puede entender el párrafo antes de cambiarlo aclarando el tema. Y muchas gracias por tus elogiosas palabras. Y me apunto a lo que le has dicho a Gencianal añadiendo que me parece inmoral una sociedad en la que CR7 (y no tengo nada contra él) vaya a ganar más en una año que lo que pudo ganar Severo Ochoa a lo largo de una vida dedicada a la ciencia de élite, capitalizadas las pesetas y dólares de entonces a euros de hoy. Y si lo comparo con los miles de padres y madres mileuristas con contratos temporales casi que me quedo corto en mi apreciación.
Saludos jreguart, claro, yo tampoco soy un experto, asi que es un placer intentar entenderlo. Si estamos de acuerdo en que en la primera casuistica no afecta la longitud, en la segunda, razonare por agentes por separado. No creo que la radiacion se vea afectada, es un fenomeno general, cuanto mayor es la diana, mayor numero de impactos ocurriran, asi que la probabilidad de que afecten a zonas activas no se reducira. Si pensamos en agentes quimicos, yo diria que es una cuestion de escala, supongo que ha mayor longitudes de cadenas el resto de componentes quimicos del nucleo aumentaran tambien, por eso de que a las celulas eso de equilibrios quimicos les gustan bastante, pero no lo se. Si hablamos en concentraciones, otra vez nos encontraremos con mas radicales libres cuanto mayores sean las cadenas, claro que esto no lo tengo nada claro. Lo de los virus no le veo muy claro, si que es mas posible que la incursion del virus no afecte a una parte activa de la cadena, pero eso es bueno? Quiero decir que si pienso en plan evolutivo, una cadena que estuviera compuesta solo de componentes activos y que una incursion en la cadena de un virus mandase al traste una importante funcion de la celula, impediria en gran medida la expansion del virus, asi que un poblacion de celulas que evolucionase hacia ese estado seria mucho mas resistente a la expansion de virus que sus vecinas con cadenas mas largas. Quiero decir que lo mejor para un tipo de celula seria que cuando el virus llega a invadir su adn esta explotase (metaforicamente) y no produciese nuevos virus. Pero supongo que esto se podria discutir mas.
En fin, que se podria discutir si la proteccion es estrictamente siempre positivo, desde luego una celula que alcanzanse una proteccion de su informacion genetica y perfeccionase su funcionamiento para evitar que se produjeran mutaciones seria una especie estancada y cualquier cazador que se fuera especializando con mutaciones en cazarla acabaria acabando con ella. Todo es cuestion de equilibrio. Yo creo que si hay genes “basura” tiene que ser en gran medida por “indiferencia”, aunque quiza simplemente lleve un tiempo ir borrando esas partes, al fin y al cabo hablamos que durante una reproduccion se produzca una mutacion que elimine parte de la informacion no util, pero esa celula no va a tener mucha ventaja, un rendimiento quimico un poquito mejor, ridiculamente mejor, creo que tardaria bastante, incluso habalndo en terminos evolutivos que se impusiese.
Respecto al otro tema, estuve dandoles vueltas ayer y la verdad es que se me ocurrio algo gracioso, que pasaria si los centros de investigacion intentasen seguir el ejemplo del futbol? Es decir, unos tios corriendo detras de una pelota, no es gran cosa, pero le han dado tanta historia, se lo han montado tan bien que mira toda la atencion y emocion que manejan, y eso lleva bastante dinero con ello. Yo que se, si los laboratorios hiciesen competiciones (mas referencias?), trofeos, batas distintas cada laboratorio, fichajes millonarios de cientificos de un laboratorio a otro, salas de conferencias gigantes llenas de gente seguidora del laboratorio jaleando los ultimos resultados, periodicos especializados saliendo cada dia explicando la actualidad cientifica, programas de discusion donde forofos discutiesen su teoria actual (“publicacion y probeta”?(discusiones en los bares criticando a los jurados o a las comisiones de expertos de las revistas)), cientificos famosos anunciando pan bimbo, ninos en bata reproduciendo experimentos sencillos en el parque… En fin que seria un camino largo, llevaria mucho tiempo llegar a la gente (cosas como el tamiz ayudan) y a saber si seria mejor o peor para la ciencia el cambio, pero no me parece que fuera imposible lograrlo y en ese caso los grandes cientificos cobrarian tanto como ahora cobra CR7 y compania, serian aclamados en los aeropuertos y al volver a casa despues de recoger un nobel los pasearian en autobus por la castellana. Mi cuestion es, que impediria a un forofo del laboratorio que sea (con su bata a rayas rojas y azules con publicidad de Spaceline Marte (para cuando pase eso igual ya existe Spaceline Marte)), llegar a casa, ponerse la camiseta del murcia e ir al estadio a ver futbol? Cobrarian menos los futbolistas en ese caso? Respecto a los mileuristas, pues pienso mas o menos lo mismo, “si la gente se organizase en sindicatos de esos de verdad, reclamase sus derechos y cobraran decentemente, eso bajaria el sueldo a los futbolista? Por que es inmoral que cierta gente tenga un gran exito?
Hola Sergio. Dejo un poco en stand by el tema. Y no para olvidarlo ya que si al final no tengo claros los fundamentos voy a eliminar el párrafo. Y te digo que he abierto un paréntesis pues estoy intentando conseguir más información sobre el tema. Ya te avisaré si aclaro algo. Con respecto al tema paralelo y tu última frase, creo que es inmoral, o llámalo como prefieras, las diferencias abismales con que nuestra sociedad reconoce los esfuerzos y los éxitos. Evidentemente que deseo que la gente saboree el éxito de sus esfuerzos. Pero esto daría tema para compartir ideas en otro entorno. Gracias por tu participación.
Sergio, creo que cometes un error de concepto con las probabilidades. Voy a desgranarlo.
La radiación es la que es: vamos a estar expuestos a X radiación a lo largo del tiempo. Esa X radiación se va a repartir entre Y o 2Y pares de bases: es evidente que cuanto mayor sea la longitud de la cadena, menor es el riesgo de mutación en el ADN activo. Es cierto que un ADN más largo ocupa algo más de espacio, pero no es tanto como parece. El ADN se empaqueta en un volumen, así que el aumento del radio será en un factor de raíz cúbica, no lineal: con lo que se puede decir que disminuye más el riesgo de mutación por “dilución” que lo que aumenta por incremento de volumen.
Aparte, el empaquetamiento del DNA aumenta cuando mayor es el DNA. Una bacteria tiene el DNA libre, sin enrollar, con lo cual lo tiene más expuesto; sin embargo el DNA humano está superenrrollado con la ayuda de proteínas, las histonas. O sea, está inmerso, enrollado, en torno a una matriz proteica, que además hace como escudo, con lo que eso ayuda a protegerlo al disminuir los riesgos de estar “en disolución”.
Las mutaciones químicas se deben a los radicales libres, y estos son dependientes del estrés celular, no del tamaño del DNA. Podemos decir que la influencia de tener un DNA más largo es incluso hasta favorable porque de nuevo tocan a más pares de bases por radical libre. Es posible que aumente algo el estrés oxidativo si hay más síntesis de nucleótidos y todo eso, sí, pero la célula no sólo sintetiza nucleótidos, estos supondrán un X% de su metabolismo. Si se dobla el nº de pares de bases podemos decir que el estrés aumenta en un 2*0,x, lo que es menos que decir que se dobla, así que se gana protección.
En cuanto a lo de los virus, Sergio, no consideres a una célula como un organismo. Muchas veces los virus, de insertarse en un lugar incorrecto, producen mutaciones que derivan en cáncer. De hecho son uno de los aceleradores del proceso originario del cáncer. En ese sentido, al organismo le conviene diluir el posible impacto de los mismos. Piensa que en un “ente pluricelular” lo que interesa es que la mayoría de las células trabajen de forma coordinada, evitando que las “egoístas” que van a su bola disturben el equilibrio. Cualquier forma de protegerse de las egoístas es positiva. No olvides que las únicas mutaciones que “importan” en términos de descendencia son las producidas en las células reproductivas, y éstas (al menos las femeninas) tienen un metabolismo basal muy reducido para evitar mutaciones. Fíjate por ejemplo lo que tardan en madurar los óvulos.
Vamos, yo no veo incorrecto lo que pone reguart con las probabilidades.
Lo del tema social mi opinión es tajante. Mientras el fútbol profesional no pague lo que debe (haciendo así que los demás tengamos que pagar más para mantener el Estado) y no tenga la deferencia de ser más respetuoso con la coyuntura actual, conmigo que no cuenten. Me parece vergonzoso que se gasten 100 millones de euros en un jugador: con ese dinero se pueden pagar 250.000 subsidios de desempleo. O si lo prefieres, el subsidio de 20.000 parados durante un año. Si ya el número es escandaloso, viendo como tantos científicos tenemos que emigrar, ya ni te cuento. Con los 3.600 millones que debe la 1ª División a Hacienda, financiamos el CSIC varios años.
@Gencianal:
Sobre lo de los futboleros y los científicos… XACTO!!!!
Estoy completamente de acuerdo contigo. Mientras no se pongan al día con Hacienda (y no lo van a hacer en muuuucho tiempo), me parece no ya poco ético, sino absolutamente escandaloso que se paguen las cantidades que se pagan, tal y como está el país y el mundo.
Y mientras tanto, por ejemplo, las chicas del waterpolo son campeonas del mundo y no cobran un duro de nadie, nadie las patrocina y apenas tienen subvenciones.
Y de los científicos, ya, ni hablamos, claro.
En fin
Conmigo que no cuenten tampoco.
jreugart, esperare a ver que consigues descubrir, yo tambien voy a intentar informarme mas por mi cuenta, aunque siempre podemos contar con que gente como gencianal nos heche una mano.
Gencianal, cuando hablamos del nivel de radiacion al que estamos expuestos a lo largo del tiempo hablamos de un flujo de energia por unidad de volumen, la absorcion de radiacion, por su parte, esta relacionada con la densidad ademas de con el nivel de radiacion (lo que explica por que es mas efectiva como proteccion una pared de plomo que una de madera), asi que en ultima instancia lo que importa para determinar la absorcion de radiacion es la masa en si, una cadena muy compacta tendra menos volumen pero mas densidad, asi que su absorcion de radiacion sera un factor del numero de nucleos, al igual que una diluida. Una cadena mas larga absorvera mas energia por radiacion sometida al mismo nivel. Respecto al escudo , por lo que leido, no es el ADN lo que esta por fuera de las histonas? De todas formas hablamos siempre de cadenas de ADN parecidas, la cuestion no es que cambie su estructura, es solo que sea mas larga y no creo que una capa o doscientas de proteinas se pueda considerar que reduce el nivel de radiacion detras de ella.
Ya habia comentado que no veia claro que el numero de radicales libres tuviese que aumentar al aumentar el tamano de ADN, claro que como dices depende del metabolismo, pero no creo que sea del de toda la celula, sino mas bien del que ocurra cerca de la propia cadena, por que creo que los radicales libres son absorvidos bastante pronto. Asi que si consideramos el metabolismo que ocurra solo en el nucleo, igual el porcentaje correspondiente a sintetizar nucleotidos sea algo mayor, o sea totalmente nulo y el ADN no este sometido a estres por radicales libres si esta en un nucleo, por que las reacciones oxidantes ocurren en otra parte de la celula.
A estas alturas continuamos con organismos unicelulares, que por otra parte son la mayoria de vida en el planeta, asi que, por que no considerar una celula como un organismo? Ya se que el cancer es malo, pero la enfermedad que produzca el virus es peor. Creo que a cualquier organismo pluricelular le convendra mas protegerse de virus que del cancer. Vamos, son formas de verlo, eso de que al organismo pluricelular le importa algo en absoluto no es tan obvio como parece, te recomendaria leer el gen egoista de Richard Dawkins, ya que es una interpretacion bastante atractiva. Sobre las celulas reproductivas, se podria decir lo contrario refiriendose a las masculinas?
Lo del tema paralelo, como bien dice jreguart, es como para tratarlo en otro entorno.
Respuesta a Sergio B. y Gencianal. Tras el interesante y enriquecedor intercambio de opiniones acerca de ciertas “bondades” del ADN no codificante (el basurilla) creo que no me queda más remedio que llegar a una conclusión personal. Creo que a pesar de la calidad de vuestros razonamientos estaréis conmigo que no surge nada definitivo y concluyente. Al menos yo soy incapaz de ver claramente si el ADN basura puede comportarse como un “escudo” frente a mutaciones que pudieran ser agresivas si se dieran en el ADN codificante. Y leyendo todo lo que he podido encontrar tampoco no veo nada concreto al respecto. Así que veo como lo más correcto el eliminar el párrafo que ha suscitado la duda. Sin embargo en el camino he tenido la suerte de contactar entre otros con el biólogo y profesor de la universidad de Santiago de Compostela Xurxo Mariño Alfonso que me ha abierto los ojos con un interesante argumento que creo no le va a molestar si lo transcribo aquí:
“Si dejamos a un lado los procesos epigenéticos (mediante los cuales el entorno puede modificar la expresión de determinados genes), en el mecanismo de selección natural es muy importante tener en cuenta un detalle, sutil pero esencial, que normalmente se pasa por alto: las mutaciones en los genes que, por algún cambio en el entorno, tienen algún valor adaptativo y a la postre se convierten en beneficiosas, ocurren ANTES del cambio en el entorno que las desenmascara.
Es decir, ahora mismo todos los animales poseemos YA mutaciones en el ADN. El que esas mutaciones pasen sin pena ni gloria o bien que se conviertan en genes funcionales y más o menos estables de una especie, dependerá de las condiciones que imponga el entorno. Si hay un cambio importante en éste, y la mutación se encuentra en condiciones de ser expresada genéticamente, entonces ésta puede desenmascararse y convertirse en ADN codificante “normal”.
O dicho de otro modo, en el proceso evolutivo la conformación física de los distintos genes no se produce a posteriori de los cambios en en el entorno; no puede ser así. El material genético tiene que estar ya ahí, dispuesto a ser perfilado por las condiciones ambientales. Podemos imaginar este material genético como una baraja aparte de la baraja oficial (la oficial sería el ADN codificante y sus adláteres): esta baraja extra tiene en principio una tasa de mutación similar a la del resto del ADN, pero los cambios que ocurren en ella pasan desapercibidos y no tienen relevancia, a no ser que en algún momento alguna de esas partes del ADN se exprese y el resultado de esa expresión tenga algún valor adaptativo.
Entonces ahora surgen varias preguntas:
¿dónde está ese material genético YA mutado que todos llevamos?: intercalado con el resto del ADN funcional. Podemos llamarlo “ADN basura” si queremos (por cierto, esto no excluye que también exista material genético con mutaciones en el ADN codificante; por supuesto).
¿cómo puede parte de ese ADN “activarse” y expresarse?: por alguno de los distintos mecanismos que hay de recombinación y transposición.
Esto nos lleva a varias consideraciones:
en un organismos en que todo su ADN sea funcional y codificante, cualquier mutación es susceptible de causar modificaciones “visibles”, lo cual limita bastante el “barajado” genético productor de variabilidad y de genes “a priori”.
por lo tanto, el “ADN basura” puede ser muy útil y funcionar como repositorio de material genético“.
Hasta aquí lo del profesor. Tal como lo veo esta idea da un giro sustancial al hecho de considerar al ADN basura como un elemento de defensa frente a mutaciones, pasando de lo que yo describía como una defensa ante amenazas a una defensa llena de oportunidades y absolutamente crucial para la evolución del individuo.
Así que quito párrafo y añado uno nuevo recogiendo la idea de Mariño.
Escribe un comentario