
Como comenté en el artículo anterior, a principios de los ochenta me cambié a otro Banco que estaba comenzando a escribir de nuevo su Sistema Informático. Este Banco tenía un Sistema funcionando, similar al que os describí en esta entrada, aunque de otra marca, y había decidido cambiarlo para que todas sus Operaciones fueran Online, es decir, eso que ahora damos por sentado: que toda operación que hagamos en un banco cualquiera se refleje inmediatamente en nuestra posición en los ordenadores centrales. No muchos bancos del mundo tenían Sistemas Online al comienzo de la década de los ochenta (y prácticamente todos, al final).
En este artículo describiré someramente el método de trabajo que usábamos durante estos años, método que cambió radicalmente a mediados y finales de la década, con la adopción generalizada del PC en la empresa, lo que contaré, si tenéis la amabilidad (y la paciencia) de seguir escuchándome, en próximos episodios.
En primer lugar, unas líneas (bueno, muchas líneas, ya sabéis que yo no sé resumir…) para contaros cómo trabajaban Bancos y Cajas de Ahorro a finales de los años setenta y principios de los ochenta.
Todos fueron completando más o menos su Sistema de Información a lo largo de la década, y todas las Aplicaciones importantes estaban funcionando, pero pocos tenían alguna parte online.
Cada oficina llevaba exclusivamente la posición de sus clientes (si querías hacer una operación en una oficina que no fuera la tuya…lo llevabas claro). Esta posición se actualizaba en unas fichas de cartón bastante grandes (unos cuarenta por treinta centímetros, recuerdo), que ya no se actualizaban a mano (bueno, en algunas entidades, todavía sí), sino con unas máquinas específicas para ello, de las que había una o dos por oficina.  Estas aparatosas máquinas imprimían los movimientos y la posición resultante en la ficha, y además grababan la información del saldo de la cuenta en la una pequeña banda magnética que la propia ficha de cartón llevaba a un lado, donde se guardaban esos datos.
Estas aparatosas máquinas imprimían los movimientos y la posición resultante en la ficha, y además grababan la información del saldo de la cuenta en la una pequeña banda magnética que la propia ficha de cartón llevaba a un lado, donde se guardaban esos datos.
No he encontrado ninguna imagen, pero podéis imaginaros una especie de “Libreta de Ahorro Gigante“, con una sola página, y su banda magnética al dorso. Pues algo parecido. En realidad eran DOS cartones, separados con papel de calco para pasar lo impreso a la copia. Cuando un cliente pedía los movimientos… se cortaba con unas tijeras el trocito de la copia donde estaban reflejados los apuntes pedidos y se le entregaba el pedazo. Con suerte, hasta se podía leer lo que ponía. La pinta que tenían estas máquinas eran algo parecido a la máquina de contabilizar de IBM de aquí al lado. (No es lo mismo, pero no encuentro nada mejor).
Comenzó a ser corriente en la época que los bancos tuvieran en las oficinas, al menos en las más importantes, ciertos mini-ordenadores especializados en las Aplicaciones más cruciales: Cuentas Personales, sobre todo.
Cuando digo “especializados” me refiero a que estaban programados con el software adecuado para esa única aplicación. De muy escasa capacidad (16, quizá 32 Kb), discos flexibles (de esos grandes, no los de 5,25 pulgadas) de algunos cientos de Kb, y programados en lenguajes específicos de cada uno, generalmente ensambladores endemoniados (al menos para mi gusto), servían para mantener la posición de los pocos miles de cuentas que podía tener una oficina normal de la época.
Mantenían el saldo, validaban y anotaban los movimientos (ingresos, cheques, recibos de caja, etc), eran capaces de imprimir un extracto a petición… en fin, podían resolver el 95% de la operativa normal de la oficina con sus cuentas, “casi” online; al menos, desde el punto de vista del cliente, lo era.
En realidad supusieron un enorme avance cualitativo: antes, para saber si cierta cuenta tenía o no saldo para responder a un pago (y siempre en la propia oficina donde la cuenta estaba abierta) el Cajero tenía que levantarse, ir a la gaveta de las fichas (las de cartón), y mirar qué saldo había allí reflejado; como los movimientos no se anotaban inmediatamente en la ficha, sino que se “pasaban” generalmente al final del día, podía haber desagradables sorpresas por haber pagado varios cargos contra el mismo saldo, y otros inconvenientes similares.
Con estos minis se podía consultar el saldo y ¡actualizarlo! inmediatamente, y sin que el Cajero se levantase de la silla (bueno, no para mirar el saldo, pero sí para comprobar la firma; lo que pasaba es que el cajero conocía al 90% de los clientes de la oficina, así que no necesitaba casi levantarse para este menester). Los responsables de los Bancos se dieron cuenta palpable de que tener sus saldos online era realmente una ventaja competitiva. Un gran avance, en definitiva.

Anuncio de módem revolucionario en 1972
Además, al final del día eran capaces de transmitir telefónicamente los movimientos a la central. Casi siempre por Red Conmutada (una llamada de teléfono a uno específico en Proceso de Datos central, y obtenida la comunicación, transmisión de los datos, por lo general vía tonos audibles, a una velocidad que rara vez pasaba de 1200 bps (o sea, 150 caracteres por segundo)… y sin ningún tipo de codificación, que yo sepa: nadie estaba entonces preocupado por el robo de información por la línea: ni siquiera sabíamos que eso pudiera llegar a hacerse…
Aquí al ladito podéis disfrutar de un anuncio de un módem de 1200 bps de 1972. ¡Vaya tela!, decir que un módem puede ser sexy… sobre todo ese módem….
Una vez acabado el envío, en Proceso de Datos (realmente, en Grabación) se grababa el fichero recibido en una cinta magnética, y ésta se enviaba al Ordenador Central para ser procesada. Este sistema permitía tratar los movimientos del día en el pase nocturno del propio día, lo que representaba un gran avance sobre el Sistema tradicional: apuntar los movimientos del día en un formulario (por algo a los movimientos bancarios se los denomina “apuntes”), enviarlo por valija a la central, mediante una especie de mensajeros que había entonces para el envío urgente de este tipo de documentos, y allí ser grabado en el Departamento de Grabación, para generar el fichero en cinta con los movimientos… de dos o tres días atrás.
Además, había el problema de que estos minis eran tan caros (y su mantenimiento, tan costoso, sobre todo en las oficinas que no estuvieran situadas en Capitales de Provincia) que no era factible instalar este Sistema en todas las oficinas, sólo en las realmente grandes que justificaran su coste.
En este estado de cosas, era evidente que el proceso online de toda la información reportaría grandes ventajas a la banca (y también al resto de grandes empresas, naturalmente), y además a un coste mucho más razonable que por el procedimiento explicado.
Así que todas las entidades se embarcaron por aquellos años en desarrollar su Sistema de Información online. Cada una, el suyo, desde luego.
Y la mayoría, usando mainframes de IBM (muchas ya tenían ordenadores de esta marca, otras aprovecharon para cambiar), y muchas de ellas, los miniordenadores especializados en banca (terminales financieros) de la propia IBM (aunque también los había de otras marcas y se integraban bastante bien).
Vamos a ver qué características tenía el Sistema de ese (mi) Banco.
Pero antes un inciso: en este comentario, nuestro amigo Jimmy Jazz nos avisaba de la existencia en red de una serie de interesantes artículos escritos por un Administrador de Sistemas, Urtzi Larrieta (kujaku), donde cuenta con bastante detalle temas sobre el mainframe, su Sistema Operativo y otros productos básicos. Enlazaré a ellos en los lugares oportunos para que podáis ampliar información si lo deseáis. Todos son muy recomendables.
.

Circuito Lógico de un IBM308x.
Bien. El Ordenador central era un mainframe de IBM.
En mi caso (o más bien, en el del Banco donde trabajaba por entonces), un IBM 3081, pero según fuera la fecha de la compra, sería un modelo u otro (antes, 370, 3031, 3033, 4341, 4381, y más adelante, el resto de la gama 308x, 3090, 390, etc), de menor o mayor potencia en cada caso.
En realidad, el que sea un modelo u otro no importa mucho, puesto que todos ellos son compatibles hacia adelante, y lo que funciona en uno lo hace también sin cambio alguno en todos los modelos posteriores, y por tanto, más potentes (lo que continúa siendo igual en nuestros días).
Esta característica facilita enormemente el cambio de un ordenador obsoleto a otro más moderno, al tener la seguridad de que todo el software (sobre todo, el que tú has escrito) funcionará sin problemas.
Aquél 3081, cúlmen de la miniaturización en 1980, tenía dos procesadores y 16 Mb de memoria, muchos canales de entrada/salida (no recuerdo cuántos), varios Gb de espacio en discos magnéticos, cuatro unidades de cinta magnética, y una velocidad de proceso nunca vista: sus ciclos de reloj eran de 26 nanosegundos, lo que quiere decir que la velocidad del procesador era de cerca de 40 Mhz… ¡en 1980!

TCM de la Serie IBM/308x
Sin embargo, tal grado de miniaturización en 1980 tenía sus inconvenientes: los circuitos lógicos despedían mucho calor. Pero mucho calor. Tanto (unos 300W por módulo, cuyo tamaño era más o menos de 6×6 centímetros) que, sencillamente, era imposible que fueran viables, pues el calor disipado fundiría literalmente los circuitos… ¡incluso provocaría un incendio!
Así que para solucionar este serio problema, IBM introdujo en su gama 308x (el primero de ellos fue el 3081) los TCM’s (Thermal Conduction Modules), diseñados para disipar eficientemente el calor generado.
Todos los circuitos del sistema, como los procesadores, controladores, canales de entrada/salida, etc, estaban encapsulados en los TCM’s, cerrados herméticamente, y rellenos de helio (no, líquido no, gaseoso), el mejor conductor de calor que encontraron, y el propio TCM estaba a su vez externamente refrigerado por agua enfriada, que circulaba constantemente accionada por bombas hidráulicas, casi como si se tratara una diminuta central nuclear.
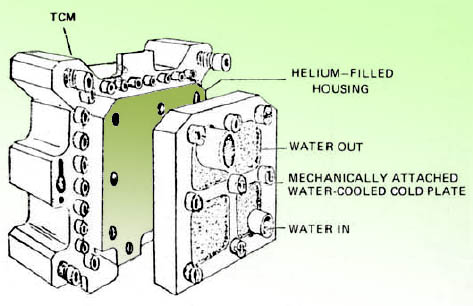
Diagrama de un TCM
Aquí tenéis un diagrama del dichoso TCM, donde se indica el contenido de helio, las entradas y salidas de agua… Curiosos, estos ordenadores refrigerados por agua. Nosotros siempre hacíamos el chiste fácil, llamando a la Sala y preguntando por el Fontanero de Sistemas… En estos tiempos parece casi una extravagancia, pero en aquél tiempo la tecnología no daba para más.
Y sin embargo esta tecnología, un tanto aparatosa, funcionaba muy bien. Eran ordenadores fiables, que rara vez tenían un problema, y cuando lo tenían, la reparación era muy rápida: se cambiaba el TCM completo donde estaba el problema por otro idéntico, y listo. Por cierto, esta vez la primera vez que el mantenimiento en ordenadores se basó en sustituir la pieza averiada por otra de repuesto, en lugar de reparar la pieza rota, polímetro y soldador en ristre, que era lo normal hasta entonces.
Esta técnica de mantenimiento “por recambio”, y no “por reparación”, se impuso, y dura hasta nuestros días. Su sucesor, el IBM 3090, también se mantenía de esta manera, aunque estaba ya refrigerado por aire. Por aire frío. Muy frío.
El ordenador era muy potente, cierto. Pero como siempre ocurre, lo que lo hacía de verdad un gran ordenador era su software. Veamos:

El Mes-Hombre Mítico. Fred Brooks.
El Sistema Operativo era, en casi todos los casos, MVS (entonces se llamaba MVS a secas, años más tarde se llamó MVS/XA -por cierto, MVS/XA fue la primera versión que permitió “romper” la línea de los dieciséis Mbs en un solo trabajo, al comenzar a utilizar 31 bits para direccionamiento, en vez de los 24 bits que se usaban hasta entonces-, años después MVS/ESA, luego OS/390, y ahora se llama z/OS, que direcciona ya con 64 bits… pero mayormente sigue siendo el mismo, muy evolucionado, eso sí).
Si queréis saber más sobre cómo se desarrolló (que yo sepa, de la nada) este Sistema Operativo, nada como leer “El Hombre-Mes Mítico” (“The Mythical Man-Month“) de Fred Brooks, director del proyecto de desarrollo del OS/360, que más adelante se acabó convirtiendo en el MVS.
Este es un libro de culto entre los informáticos, pues en él Brooks habla de sus experiencias dirigiendo el mayor proyecto de desarrollo de software jamás realizado hasta entonces (más de 3.000 años hombre de esfuerzo).
Si la frase “Añadir recursos a un proyecto retrasado sólo conseguirá retrasarlo más” os suena de algo, pues es de Brooks. Y el libro se publicó ya en 1975…
Como Gestor de Bases de Datos, se usaba IMS/DB, también conocido como DL/1 (aunque en realidad DL/1 -por “Data Language/1″- era el Lenguaje de manipulación de la información en la Base de Datos). IMS/DB es (aún quedan por ahí aplicaciones escritas en DL/1) una Base de Datos jerárquica, es decir, su diseño toma forma arborescente, donde cada registro (Segmento, en su terminología) puede tener “padres” (de los que hereda sus claves), “hijos” (a los que cede sus claves) o “hermanos” (otros hijos del mismo padre, que están físicamente ordenados entre sí por algún criterio o clave).

Representación de un texto XML
Esta Base de Datos no es sencilla ni de diseñar ni de programar correctamente, pero una vez hecho tiene un rendimiento extraordinario, y fue capaz de sacar un excelente partido a los ordenadores de la época (de limitadísimas capacidades si lo comparamos con cualquier ordenador actual, incluyendo el que tú, lector, tienes encima de la mesa…).
En el mercado había alguna otra Base de Datos por entonces, todas jerárquicas o en red, pero IMS fue la que mayor éxito comercial tuvo, sobre todo en los ordenadores de IBM, por motivos obvios.
Por cierto, sé que la mayoría de vosotros, sufridos lectores, estáis convencidos de que las Bases de Datos Jerárquicas han pasado a la historia, fagocitadas por las hoy omnipresentes Bases de Datos Relacionales, pero quizá cambiéis vuestra opinión cuando penséis que el hoy tan usado lenguaje XML es, en realidad, puramente jerárquico. Para almacenar información descrita en XML (información en serio, quiero decir) es mucho más eficaz utilizar una Base de Datos Jerárquica, que no una Base de Datos Relacional, donde para plasmar la Jerarquía, se precisan tablas de relación entre tablas, lo que hace la solución mucho menos eficaz: para recuperar una rama completa del árbol es preciso hacer join tras join… y los joins no suelen ir muy rápido, precisamente. Cuando tenemos miles de registros, no importa demasiado, pero si tenemos almacenados decenas o cientos de millones, entonces sí que importa.

IBM 3705. Panel de control.
Las comunicaciones con oficinas se hacían mediante una Unidad de Control de Comunicaciones IBM 3705, en la que funcionaba el NCP (Programa de Control de Red), que permitía llevar el control de las comunicaciones con los terminales liberando al mainframe (y sobre todo, a su software) de llevar ese control.
El protocolo de comunicaciones era IBM SNA, que permite comunicaciones síncronas (bajo SDLC) con un bajo overhead de comunicaciones. Ni de lejos es tan potente como TCP/IP… pero era perfecto para las líneas de la época: punto a punto con cada oficina, de 4.800 ó 9.600 bps, como máximo. Desde luego, también las comunicaciones han mejorado bastante desde entonces.
Toda la gestión de sesión la hacía el VTAM, residente en el mainframe, que era el que “repartía juego” entre las diferentes aplicaciones: el IMS, el CICS, el TSO, o incluso las aplicaciones RJE, las que permitían imprimir listados obtenidos en el host por impresoras que estaban físicamente en oficinas, ahorrando una fortuna en transporte de los documentos.
El Gestor Transaccional era IMS/DC. Otra posibilidad de la propia IBM, de origen más antiguo, era CICS, aunque el diseño del CICS estaba más orientado a pequeños sistemas transaccionales, mientras que el IMS lo estaba a los verdaderamente grandes… aunque en la actualidad, tras treinta años de mejoras, ambos tienen capacidades similares.
Un Gestor Transaccional es el Subsistema encargado de recibir las transacciones (operaciones elementales) que se producen en las oficinas, y garantizar su proceso correcto. Transacciones son las operaciones elementales (un ingreso de efectivo en una cuenta, un pago por cheque, un cambio de domicilio, una consulta de movimientos… las miles de posibles operaciones que realizan los bancos cada día son todas transacciones). El Gestor Transaccional tiene que:
1 Reconocer de qué transacción se trata para asociarla al programa que la sirve.
2 Gestionar las colas: en momentos de gran tráfico, es posible que se reciban más transacciones por segundo de las que se puede despachar, por lo que debe poner las transacciones individuales en su respectiva cola y gestionarlas.
3 Invocar cuando le toque, según su prioridad, al programa, que leerá los datos de la transacción concreta de la cola para procesarlos.
4 Gestionar los accesos que el programa haga a las Bases de Datos, teniendo en cuenta posibles concurrencias, bloqueos, fallos de programa, etc.
5 Cuando el programa termina, enviar la respuesta al terminal de origen, con sus correspondientes colas de salida, y las mismas funciones que las de entrada. O también insertar en la cola de entrada un mensaje para arrancar otra u otras transacciones, para que hagan alguna función (avisar a un supervisor, por ejemplo), o que terminen el proceso…
6 Y cuando el programa falla (en ocasiones, aunque no os lo creáis, los programas cascan), recuperar todos los cambios que haya podido realizar, para dejar los datos como si nada se hubiese ejecutado.

Diagrama del Sistema Financiero IBM 3600
Y todo esto, ejecutando muchas transacciones simultáneamente. Decenas, o centenares, o miles de ellas por segundo. Con un tiempo de respuesta normalmente por debajo del segundo. Al cabo del día, serán varios millones de transacciones las que habrá tratado un solo IMS/DC… sin pestañear y sin caerse. Aunque casquen los programas que dan servicio a las transacciones, por el motivo que sea (que eso sí que pasa, que al fin y al cabo los programamos nosotros), el IMS en sí ni se inmuta. Un programa bien hecho, el IMS.
Por fin, en las Oficinas del Banco había efectivamente unos miniordenadores específicos para la gestión de las transacciones bancarias: el sistema financiero IBM 3600.
Se trata de un servidor (de gran tamaño físico para lo que estamos ahora acostumbrados) con conexión por cable coaxial a los terminales bancarios de la oficina, y por línea punto a punto (entonces, como máximo, de 9600 bps, o sea, 1200 caracteres por segundo) a la central… o a otras oficinas más pequeñas, a las que daba servicio (con el correspondiente ahorro importante de costes).
Por la línea envía las transacciones (las operaciones que se ejecutan) y recibe las respuestas (que se llamaban “Reacciones”); por los terminales realiza la captura de las transacciones, una cierta validación de forma (que no falten campos obligatorios, que las fechas sean correctas, y poco más) e imprime los documentos bancarios y la hoja de fondo.
Esto hoy en día puede parecer una tontería, pero eran capaces de imprimir en papel continuo, en la hoja de fondo, toda la información de control (para cuadres, auditorías, etc), y validar por la impresora de documentos los resguardos para los clientes. Se trata de otra impresora diferente (¡que, en 1980, no era de papel continuo!, sino que se “come” el documento, lo imprime, y luego lo devuelve: tecnología punta de la época) y era una característica novedosa que aportaron esos sistemas especializados, que, como podéis suponer, se programaban en su propio Ensamblador endiablado, para variar.
.
Bien, ahora que he descrito sucintamente el paisaje, voy a contar a qué se dedicaba el paisanaje, es decir, cómo diseñábamos, programábamos, probábamos y poníamos en Producción las Aplicaciones en este entorno novedoso para mí (aunque no tanto, pues en la Carrera habíamos estudiado bastantes de las características de estos ordenadores, y no me resultó tan desconocido).
¿He dicho ya que todo el software se hacía ex profeso para cada empresa? Lo dije hablando de los años setenta, y lo repito al hablar de los ochenta. Pero lo que sí estaba cambiando rápidamente era la forma de diseñar y escribir el software. No sólo los medios técnicos eran mucho más avanzados, sino que el propio método que seguíamos era más avanzado.
Todo el Sistema de Información fue diseñado completamente por profesionales del Banco ayudados por Técnicos de IBM con experiencia en banca, y programado por programadores del Banco, todo a lo largo de tres o cuatro años. O cinco… El Plan de Formación previo fue exhaustivo, pues todo el personal de Proceso de Datos del Banco, así como las nuevas incorporaciones como yo, pasamos varios meses aprendiéndonos de arriba abajo el nuevo entorno técnico.
El método de trabajo que seguíamos entonces era, aproximadamente, el siguiente:
Los Analistas Funcionales (ya no necesariamente “Jefes de Proyecto”), casi todos del Departamento de Organización y Métodos, escribieron el Análisis Funcional de las distintas Aplicaciones: Cuentas Personales, Contabilidad, Valores, etc. No había directrices claras sobre cómo escribir estos documentos, así que cada analista lo escribía como sabía y como podía. Ahora lo llamaríamos más bien un “Análisis de Requirimientos”. A veces eran muy detallados en la descripción de la operación elemental, y a veces terriblemente ambiguos… (claro que ahora sigue pasando lo mismo, je, je). La colección de estos “Análisis Funcionales”, junto con las especificaciones de la solución técnica formaba el “Plan de Sistemas”, piedra angular a la que todos nos referíamos cuando había discrepancias. Que las había.
Terminado el Análisis Funcional/de Requerimientos, se realizaba el Diseño Técnico de la Aplicación. Esto consistía en las siguientes tareas:
1 Diseñar las Bases de Datos IMS de la Aplicación. Un punto crítico, porque un fallo en el diseño inicial podría costar muchísimo tiempo y esfuerzo (y por tanto, dinero) en corregirlo, una vez terminados los programas.

Diseño de una Base de Datos IMS/DB
Gastábamos muchísima saliva en interminables reuniones para determinar, entre todos, el mejor diseño posible teniendo en cuenta los requerimientos, el número de transacciones esperadas, etc. Y tengo que decir que al final casi siempre llegábamos a un consenso de diseño que, en general, era el menos malo de los posibles (porque ya sabemos que el mejor, lo que se dice el mejor, no existe…).
2 Diseñar las transacciones, es decir, qué datos deben viajar entre el terminal financiero (el famoso IBM 3600) y el Ordenador Central, para minimizar el tráfico, pero que no falte ningún dato necesario.
3 Repartir las funciones de la transacción: qué debía hacerse en el terminal financiero y qué en el mainframe.
4 Diseñar el batch. Muy importante, porque las transacciones capturan la información, la validan y toman decisiones inmediatas, pero toda la consolidación se hacía (y en buena parte, se sigue haciendo hoy en día) en batch, en un proceso por lotes. Muchísimos procesos son netamente batch: Liquidar cuentas, Emitir Recibos, Imprimir Extractos Mensuales, Hacer el Balance de Contabilidad, Abonar Dividendos, etc, son procesos costosos que necesitan acceder a muchísima información, y donde no hay nadie esperando respuesta al otro lado del terminal. Todo esto se hace en batch.

Diagrama de un proceso batch de Actualización de un Fichero Maestro
Me sugería Rabade en la entrada anterior que debería hablar de la ventana batch (lugar donde se ejecutan la mayor parte de los procesos batch). Pero quiero dedicarle unos párrafos, puesto que es muy importante (y muy desconocida para muchos de los más jóvenes), así que le dedicaré un poco de espacio en la entrada que tarde o temprano escribiré sobre las Bases de Datos Relacionales (aunque la necesidad de la ventana batch no es ni mucho menos exclusiva de ellas).
5 Diseñar los módulos comunes. Son piezas de software reutilizables en diversas partes de una Aplicación, que se aíslan de antemano y se programan una única vez, asegurándose de que hacen perfectamente la función definida, y con la máxima eficiencia posible. Los había genéricos (como, por ejemplo, dadas dos fechas, calcular la diferencia en días entre ellas, esto se usa muchas veces en los procesos bancarios), que utilizaban todas las Aplicaciones, y otras específicas de cada Aplicación (como el módulo de Contabilización de Apuntes, que sabía a qué cuenta contable se refería cada tipo de movimiento y realizaba correctamente el apunte en la Base de Datos de Contabilidad).
6 Diseñar los programas de interfase con las Aplicaciones Antiguas. Importantísimo: Naturalmente, las Aplicaciones no se arrancaron todas a la vez; de hecho cada Aplicación tampoco se arrancaba en todas las oficinas a la vez (técnica que, por lo que yo sé, se sigue usando hoy en día). Entonces, al arrancar Cuentas Corrientes en un par de oficinas, deberían sus datos integrarse con los del resto de Oficinas (que seguían trabajando con las Aplicaciones Viejas), hasta que todas las oficinas estuvieran migradas a la nueva Aplicación. Y, en cualquier caso, esta Aplicación de Cuentas Corrientes debía comunicarse con las de Contabilidad, Valores, etc, que seguían siendo las antiguas, hasta que pudieran ser sustituidas, meses o años después. Pregunta retórica a aquellos de vosotros que estáis estudiando informática: ¿Alguien os ha contado estas cosas? Si la respuesta es Sí, podéis felicitaros, a vosotros mismos, y a vuestros profesores.
Una vez terminado este trabajo, fundamental para que todo vaya luego bien y, sobre todo para que la Aplicación resultante sea mantenible de cara al futuro, había que realizar las especificaciones de los programas individuales, para su programación. Éste fue, mayormente el trabajo que comencé haciendo allí, como “Analista Orgánico”, participando también en el Diseño Técnico de la etapa anterior. Pero si había que programar, se programaba, y si había que hacer un Funcional, se hacía. ¿He dicho ya que el objetivo de todo el equipo era sacar el trabajo adelante, y todo el que podía colaborar a hacer algo bien, lo hacía, sin preocuparse de categorías profesionales y otras zarandajas?… Y además, los fines de semana nos íbamos a jugar todos al fútbol (no, las chicas no iban) y casi, casi, no nos dábamos patadas…
Para hacer el Análisis Orgánico de los Programas (tanto los online –transacciones- como los programas batch), realizábamos los “Cuadernos de Carga” donde el Analista describía las principales funciones que debía realizar el programa. A lápiz, oiga. Para poder borrar, naturalmente.

Plantilla para pintar los diagramas de los programas en los Cuadernos de Carga
Preparamos unas hojas standard preimpresas, donde dibujábamos (con la plantilla, esta vez sí) el diagrama del programa (Bases de Datos a las que accedía, Ficheros que leía/escribía, Impresos que generaba, etc).
Después, en román paladino, describíamos con cierto detalle lo que tenía que hacer el programa de marras: Que si leer los datos de la transacción de la cola de entrada; que si validar de tal manera los datos de entrada; que si comprobar si había saldo o no en la cuenta de tal otra; qué hacer si no había saldo, o si la cuenta estaba bloqueada; cómo actualizar los saldos y los movimientos, qué responder y de qué manera a la oficina… esas indicaciones que permitían al programador escribir el programa y que casi hiciera todo lo que debía hacer…
Nos convertimos en virtuosos del copiar-y-pegar, pero literalmente, no como ahora, que es todo virtual: hacíamos una fotocopia de la página que había que copiar, recortábamos la parte que nos interesaba, la corregíamos si era preciso (con el Tipp-ex y luego escribiendo encima) y pegábamos por fin el resultante en la hoja definitiva con goma arábiga. ¡Un auténtico lujo, oiga!

Unidades de Cinta en una instalación informática (años 70 y 80)
Las transacciones online sólo podían acceder a las Bases de Datos IMS, que estaban siempre en disco, pero los ficheros Maestros seguían estando mayormente en cinta magnética (los discos seguían sin tener capacidad para guardar allá toda la información necesaria…).
Por lo tanto, para actualizar estos ficheros en cinta, mediante cadenas batch (compuestas de una serie consecutiva y secuencial de programas tuyos y programas de utilidad, sobre todo el omnipresente Sort), se utilizaba un tipo de proceso de actualización denominado “Padre-Hijo”, que ya expliqué en una entrada anterior, y que sigue siendo muy útil hoy en día, aunque casi nadie lo reconoce…
En el otro lado de la línea estaba la misma transacción, pero vista desde el terminal financiero. Había, pues que hacer otro Cuaderno de Carga (por otro Analista diferente y especializado en este Sistema Financiero), coordinándose con el del mainframe, para tratar la misma transacción, especificando aquí lo que debía hacer en el front-end, es decir, en la parte que “da la cara” ante el cliente: Definir qué campos son obligatorios y cuáles opcionales para esta transacción, cómo validarlos, cómo rellenar el mensaje para la central, enviarlo…(esperar respuesta)…, cómo procesar la información recibida del Ordenador Central, qué imprimir y dónde, etc.

Diagrama de un proceso de actualización Padre-Hijo
Los programadores recibían los cuadernos de carga una vez terminados, y comenzaban entonces su trabajo: codificar, compilar y probar sus programas. Inicialmente usábamos la misma técnica que la descrita para los NCR Century 200:
Uno: Escribir en Hojas de Codificación el programa en el lenguaje adecuado (Endemoniado Assembler en el terminal financiero, Cobol en el Ordenador Central),
Dos: Enviarlos a perforar,
Tres: Cuando los devolvían perforados, se compilaban, el listado de la compilación se enviaba al programador, etc, etc… en fin, no sigo: el mismo vetusto procedimiento que ya conté en esta entrada.
Lo que sí cambió radicalmente fue el modo en que se diseñaban y escribían los programas: Desde el principio, desde el primer programa que hicimos, utilizamos las técnicas de Programación Estructurada. Se acabaron los organigramas chapuceros, se acabó el código spaghetti, se acabaron los GOTO’s indiscriminados a cualquier parte del programa, se acabó, en definitiva, programar como a cada uno buenamente se le ocurría: se acabó la programación artesanal de décadas anteriores, para entrar en una programación más industrial, más organizada y previsible. Los programas resultaban más eficaces en ejecución, se tardaba menos en codificarlos y probarlos, y, sobre todo, sobre todo, eran mucho más sencillos de mantener.
En la actualidad “se da por supuesto” que los informáticos, y los aspirantes también, saben las normas básicas de este paradigma de diseño, pero apenas se enseña (y conoce) de verdad por los profesionales de nuevo cuño… y los viejos lo hemos olvidado…
El próximo artículo lo dedicaré a explicar esta técnica (la Programación Estructurada) con algún detalle, intentando contaros cómo empezó todo, cómo fuimos cambiando el chip, qué se fue haciendo para mejorar la programación, qué normas se ponían, y cómo nos las saltábamos…
Al principio seguimos utilizando fichas perforadas (la costumbre es la costumbre), pero las cosas cambiaron muy rápidamente. Una de las características más importantes del MVS era su TSO, subsistema de tiempo compartido que permitía, usando un interfaz de línea de comandos por pantalla (¡no en ficha perforada, sino tecleando!), acceder simultáneamente a diferentes usuarios como si todo el mainframe fuera sólo suyo… cosa que no era cierta, claro, pero lo parecía.

Terminal IBM 3270
Y rápidamente se instaló también, sobre el TSO, el ISPF que permitía, ahora sí, un acceso mediante pantalla completa, y un magnífico editor de programas (para qué mentir: el mejor que yo conozco…y mira que conozco), y que revolucionó la informática y la forma de trabajar, sobre todo de programadores y operadores (porque nosotros, los pobres Analistas, seguíamos escribiendo páginas y páginas como tontos).
Eran pantallas monocromas (de fósforo, en verde o en amarillo, según), dedicadas, conectadas con cable coaxial al concentrador de comunicaciones que, en definitiva, las conectaba con la IBM 3705, de veinticuatro líneas de ochenta caracteres, y desde luego que su interfaz no era gráfico, sino de caracteres (y sólo las mayúsculas) y a base de teclas de función (PF8, adelante; PF7, atrás; PF3, grabar y salir; PF5, buscar, y así… Y PF1 era “Help”, pero nadie pulsaba esa teclita…¡Somos españoles, qué pasa! …y preferimos gastar una hora intentando averiguar por ensayo y error cómo funcionan las cosas, antes que leer un manual… y en inglés, para más inri).
O sea, que ahora, una vez leído por primera vez el taco de fichas, el programa quedaba almacenado en una librería de programas fuente (cada programador tenía la suya propia, que gestionaba a su conveniencia, almacenada permanentemente en disco, aunque todos podíamos acceder en caso de necesidad a las librerías de los demás), y entonces, las modificaciones al programa para compilarlo hasta ponerlo a cero errores (o para conseguir que funcionara durante las pruebas), se hacían usando el editor del ISPF, y mediante pantalla (IBM 3270).

Vista de una pantalla ISPF (con el principio de un programa Cobol)
Lo que pasaba al principio es que estas pantallas eran caras (¡y grandes!… No, la carcasa era grande, la pantalla en sí era enana, de catorce pulgadas o menos), y el ordenador tampoco tenía capacidad para aguantar muchas regiones de tiempo compartido simultáneamente, así que había pocas pantallas (como media docena, recuerdo) en una Sala de Reuniones (ex-Sala de Reuniones, ahora “Sala de Pantallas”).
Los programadores iban allá con sus listados, se ponían en una pantalla que estuviera libre, editaban su programa, lo modificaban, lo compilaban, lo volvían a modificar y compilar hasta ponerlo a cero errores, y lo probaban hasta que funcionaba correctamente… ¡o hasta que se le acababa su tiempo!
Porque, claro, había bastantes más programadores que pantallas, y eran un bien escaso y bastante solicitado (peleado, diría yo), así que pronto quedó claro que había que ordenar el asunto, mediante una lista de espera donde te apuntabas, y te correspondía una hora de uso de pantalla. Al acabar tu hora, venía el siguiente y te echaba. Sin más. Como en las Pistas de Tenis: cuando se acaba tu hora viene la siguiente pareja con sus raquetas y te echa… pues igual (pero sin raquetas). Y si, cosa rara, terminabas lo que habías ido a hacer en menos de tu hora, le cedías tu pantalla a alguna programadora de buen ver, a ver si caía algo… que nunca caía (supongo que las programadoras se lo cederían a los programadores de buen ver, pero no tengo datos: nunca fui agraciado). ¡Qué jóvenes éramos, pardiez!
Con el tiempo, se fueron poniendo más pantallas, hasta diez o doce, luego quizá veinte, luego una cada dos programadores, hasta que no muchos años después (sobre 1985 o así) todos los programadores (en realidad, todos los que accedían regularmente al Sistema) tenían ya en su mesa su propio mamotreto, perdón, pantalla, lo que agilizó mucho el proceso.
Rápidamente, dejaron de perforarse los programas (con enorme alivio por parte de las pobres perforistas), y los programas se escribían ya completos en la pantalla, reutilizando partes de código similares de otros programas, inveterada costumbre de todo buen programador en Cobol. Cómo será el asunto, que hay malas lenguas que afirman que no es verdad que haya en el mundo millones de programas distintos escritos en Cobol, sino más bien millones de versiones distintas del mismo programa…
Y también, a mediados de los ochenta, llegó la hora de mecanizar los Cuadernos de Carga. No, je, je, todavía no se habían inventado las Herramientas CASE (o, si se habían inventado, no se habían puesto aún de moda, como pasó a finales de los ochenta y primeros noventa), la cosa era más rústica:

Aquí se almacenaba la documentación.
Tú, Analista Orgánico, seguías escribiendo con tu lápiz, y después una mecanógrafa pasaba a máquina los Cuadernos de Carga en uno de los primeros sistemas ofimáticos que existieron, que eran unas máquinas “tamaño mesa” con un teclado, una pantalla y discos flexibles, que funcionaban básicamente como una máquina de escribir, con un sencillo editor de texto, sólo que lo escrito no se imprimía, sino que quedaba almacenado en el disco flexible y podía ser recuperado o modificado más adelante. ¡Adiós al copiar-y-pegar-con-goma-arábiga! O no…
En cualquier caso, cuando los programas por fin funcionaban (o, al menos, lo parecía), se ponían en Producción, por un procedimiento similar al descrito hace unas entradas, sólo que ahora Sistemas (los Técnicos de Sistemas, quiero decir, que creo que eran tres) copiaban tu programa fuente y el ejecutable y se lo llevaban a una librería del Sistema, donde ya los de Desarrollo no podíamos tocarlo, sólo verlo o copiarlo.
¡Empezábamos ya a preocuparnos por cosas como la Seguridad! Si alguien nos cuenta entonces lo que hacemos ahora para garantizar la Seguridad (no, sólo para maximizarla, porque garantizar, garantizar… en fin), nos caemos de la silla.
Cuando había que modificar un programa por el motivo que fuera, seguíamos diversos procedimientos dependiendo del motivo de cambio, y, sobre todo, de la urgencia.
Si era un cambio planificado, los Analistas Orgánicos actualizábamos el Cuaderno de Carga (sí, muchas veces más copy-paste con Tipp-Ex y goma arábiga, y después, a pasarlo a máquina), y lo entregábamos al programador que lo iba a modificar, siempre que se podía, el mismo que lo escribió inicialmente, que en aquellos años aún se podía: ahora, no. Éste copiaba la versión “buena”, que está en Producción en las Librerías de Programas en Producción (donde los de Desarrollo sólo podíamos leer, no modificar nada), a su librería personal, localizaba el lugar donde tocar el código, lo tocaba, compilaba, probaba… y cuando estaba listo, daba orden a Producción para sustituir la versión del programa en Producción por la nueva. Cuando las modificaciones afectaban a más de un programa, cosa habitual, había lógicamente que coordinar el paso a Producción de todos los programas afectados a la vez, etc.

Detalle del "Prontuario de Cabecera" del programador de IBM
Pero si había que modificar un programa urgentemente (casi siempre por un hermoso casque en Producción), pasábamos de documentar nada, e íbamos derechos al criminal causante de tamaña fechoría (¡cascar a las dos de la mañana, por favor!), a localizar el motivo del casque (mirando el listado con el volcado de memoria, claro, no había otra manera), y arreglar a todo trapo el programa para continuar la normal operación.
Para ello, usábamos continuamente unos prontuarios que IBM tenía y distribuía (y ahora, me parece que no), con toda la información básica del Sistema que necesitabas para resolver el casque: la IBM 370 System Referente Card.
En ella encontrabas a mano casi todo lo que necesitabas: todos los códigos máquina de operación, los de los caracteres, formatos de instrucción, contenido de la PSW (Program Status Word, lugar donde se almacena toda la información actual sobre la ejecución del programa), los códigos de error, etc.
Otra pregunta retórica, queridos lectores que habéis sido capaces de llegar hasta aquí: ¿”S0C7” (Ese-Cero-Ce-Siete) os dice algo? ¿No? …Pues es el código de casque más famoso de todos los tiempos, y aunque leído en inglés parece más impresionante, en realidad significa, exactamente: “Chaval: has intentado hacer una operación aritmética con datos no numéricos”. Conclusión: ¡A los corrales!. Para otra vez, antes de operar, valida si los valores de los campos son realmente numéricos o no lo son, que para eso el Cobol te lo pone realmente fácil:
“IF CAMPO-TAL-Y-CUAL NUMERIC realiza la operación ELSE algo va mal…”
Fueron, desde luego, años realmente interesantes, quizá los mejores de mi vida (claro que por entonces tenía veintitantos años… ¡cómo no iban a serlo!). Y sin embargo, pasada la mitad de la década volví a cambiar de Banco. Y esta vez, fue, más que por el Proyecto (que también), por el vil metal. Pero uno quería fundar una familia, y claro… Pero esta es otra historia… y nunca será contada.
El próximo episodio lo dedicaré a contaros qué es eso de la Programación Estructurada, como ya amenacé antes. Su historia, cómo se fue imponiendo, qué tal nos adaptamos, etc… si es que el Gran Jefe Pedro sigue dando cancha a este viejo informático parlanchín.
Disfrutad de la vida, mientras podáis.

The Historia de un Viejo Informático. El método de trabajo en los ochenta. by , unless otherwise expressly stated, is licensed under a Creative Commons Attribution-Noncommercial-No Derivative Works 2.5 Spain License.


{ 29 } Comentarios
Me ha parecido otra entrada muy buena. Voy a proponer a mis ex-profesores de la universidad que recomienden la lectura de tus artículos a sus alumnos, ofrecen un punto de vista muy bueno y necesario sobre la realidad, y sobre un mundo informático “alternativo” (que no se estudia) pero que puede ser el que encuentren al salir. Además siempre es bueno conocer sus orígenes.
Yo me recuerdo ir a sacar dinero en una cuenta en la que estaba autorizado a una sucursal que no era la habitual y el cajero se colocaba delante de una maquinita que transmitia unas lineas a la oficina de destino (a la que había abierto la cuenta) preguntandole por los autorizados de esa cuenta.
Al cabo de unos minutos de espera (a veces había que repetir la operación o el cajero tenía que llamar a la oficina de destino) la maquinita escribia dos o tres lineas y me daban la pasta…
Esto era al principio de los 90.
Y para cuando hablarás del lenguaje RPG?, eso si que era horroroso y no el lenguaje ensamblador.
Genial el artículo, es un viaje increíble para un informático nacido en los 80 como yo
Por un momento me he visto sólo ante el monstruo mordiendo el polvo a las dos de la madrugada, con el volcado de memoria e intentando localizar el error… me da angustia de solo pensarlo
@Baco: ¡Buena idea! A ver si, además de enseñar teoría, enseñan también conocimientos más de andar por casa, pero que serán necesarios a lo largo de la vida laboral.
@Juan: Pues del RPG no puedo decir más allá de dos líneas: me lo perdí, nunca trabaje en un S/36, o un S/38 o un AS/400. Pero si algún lector bondadoso quiere escribir sobre RPG (que sigue en uso, por lo que yo sé, en los iSeries), encantado!!
Y estoy de acuerdo que el ensamblador es muy bonito… pero ¡Es que tú no sabes cómo eran AQUELLOS ensambladores, que no debñian tener más allá de quince o veinte instrucciones…! eran tremendos!!
Gracias por vuestros comentarios
Ya te digo yo que no, Yo que estoy acabando la carrera ahora ni me imaginaba el pollo que hay que poner para poner NADA en producción. Es ahora, en un entorno empresarial donde me está tocando aprenderlo (A base de muuucha frustración)
De nuevo ENHORABUENA. Ya estoy recomendando esta serie de artículos a todos mis amigos (bueno solo a los que les interesa esto claro…
Saludos!!
Aunque no te lo creas (o quizás sí), acabas de describir con asombroso detalle mi trabajo actual (y de unos cuantos miles más te puedo asegurar). Ay esos 0c7 de algún batch de producción a las 2 de la mañana! Bendito sort! Bendito icetool! TSO, ISPF, QMF, FileAID, SPUFI… (nada de tarjetas perforadas ufff)
Cuando escucho por ahí aquello de que cobol y el mundo mainframe está muerto, me río y pienso para dentro… si supieras lo que hay detrás de cada cajero! si supieras cómo se liquida tu tarjeta, cuenta o préstamo, si supieras en qué está escrito el programa que te permite hacer una transferencia desde la web…
Resulta curioso lo poco que ha cambiado este mundillo . Sólo espero que siga unos cuantos años más así, que al fin y al cabo es lo que me da de comer (y a unos cuantos más).
Saludos!
¿Soy el único que al ver la máquina de contabilizar de IBM le ha venido a la mente otra imagen?
http://img.geocaching.com/cache/61772e1b-254b-41a5-99f0-2f69c3daf8d5.jpg
(fijaos sobre todo en el voladizo de la parte derecha de ambas máquinas)
¿Habrá sido esa la fuente de inspiración?
@yomismo: ¡Ya lo sé! Ahora hay más herramientas (el FileAid, el AbendAid, el SPUFI, el propio DB2, que hasta 1986 u 87 no empezó a estar operativo…) pero el JCl, el ISPF, el bendito Cobol, el CICS o el IMS/TM, que siguen servicio sin inmutarse… esas son las herramientas que de verdad mueven el mundo. Y por muchos añós, creo yo.
@raster: Pues no se me había ocurrido, la verdad. Tampoco las máquinas posicionadoras eran exactamente así, pero no he encontrado ninguna foto ni esquema ni nada. Eso sí: esa contabilizadora es Preciosa!
@todos: Gracias por vuestros comentarios…
Muy bueno señor!! Cada semana miro si hay nuevo artículo (aunque estan triunfando en meneame y allí salen enseguida).
Un saludo Macluskey! Espero que tengas muchos más!! Y que cuando se te acaben sigas escribiendo
Salud!
Al menos a mi me aparece un pequeño error junto a el gráfico “Actualización Clientes”. Aparece un “Me” justo antes que debería ir justo después, donde empieza con “sugería Rábade …”
No recuerdo quien firmaba: “Con unas cuantas horas de prueba y error te podrás ahorrar unos minutos de leer un manual”
@Brigo: Gracias por el chivatazo… pero yo lo veo bien, en IE y en Firefox. El “Me” va delante de “sugería Rabade”, y después del gráfico… quizá sea un tema de configuración de pantalla, que tengas más (o menos) resolución de la que yo tengo… Es poco menos que imposible probar todas la combinaciones para que se vea bien siempre. Lo siento!
Y claro que sí. Con lo divertido que es ir probando cosa tras cosa a ver lo que funciona y lo que no… ¿O es que alguien se lee las instrucciones antes de montar un mueble de Ikea??
Saludos
Felicidades por esta nueva entrega, es apasionante. Queremos mas!!!
Por cierto:
“Diseñar los programas de interfase con las Aplicaciones Antiguas [...] Pregunta retórica a aquellos de vosotros que estáis estudiando informática: ¿Alguien os ha contado estas cosas? Si la respuesta es Sí, podéis felicitaros, a vosotros mismos, y a vuestros profesores.”
Pues te puedo decir que yo si que cuento algunas de las tecnicas de migracion de grandes sistemas dentro del tema de Sistemas Legados de la asignatura “Sistemas de Informacion” que imparto en la Universidad de Zaragoza. Ya les dire a mis alumnos que me feliciten … y que lean tus articulos, aprenderan mucho.
… y que lean tus articulos, aprenderan mucho.
Un saludo!
@EddietheWild: Pues antes de que te feliciten tus alumnos… te felicito yo!!! Porque, amigo, que sepas que eres un “rara avis”.
Saludos
Muy bueno, líder, quiero decir, Mac Enhorabuena por otra entrada gustosa de leer (¡y creo que la más larga en la historia de ElCedazo!)
Enhorabuena por otra entrada gustosa de leer (¡y creo que la más larga en la historia de ElCedazo!)
Sigue así.
Nos vemos luego. Saludos.
Me estaban pitando ultimamente los oidos y no sabía por que, ahora que leo estos artículos y a los que me hacen referencia, ya he averiguado por que, je, je.
Muy buenos estos temas, yo soy mas joven, pero fue precisamente de pequeño cuando vi por primera vez en mi vida un 4341 funcionando con VSE/SP y gente con bata blanca cambiando cintas, y otra gente sacando listados en impresoras de banda de caracteres 4245, que m enamoró perdidamente de estos sistemas, que han decantado mi vida profesional y de hobby.
Si quereis algo mas de información, podéis ir a mi web, http://www.yggdrasil.tv en el que se detallan articulos de iniciación, o incluso cronicas de desmontaje de los equipos que me llevo como hobby.
@Lucas: ¿Líder? ¿LÍDER? ¿Yo, que ni siquiera sé montar en bici?
Quiá. No, porfa… ¡Que me suena a Gran Hermano!! (no el de la televisión, por cierto: el de verdad: Orwell-1984).
Gracias por el piropo, pero ya sabes cómo pienso… y en ascuas me tienes esperando al año más impactante de la Historia de la Fïsica: 1905, y a Einstein publicando artículos destripa-teoría-existente a puñaos…
Saludos
¡Jo! ¡Me he comido los 6 artíclos uno detrás del otro!!
Yo comencé a estudiar informática en 1988, no vi nunca ninguno de estos engendros que cuentas, pero en el instituto que estudié nos enseñaron todo esto mismo, claro que antes de terminar la carrera actualizaron los planes de estudio y nosotros quedamos a caballo de lo nuevo y lo viejo. Y teníamos turnos de 1hs para usar los ordenadores… unos AppleIIe donde hacíamos las practivas en BASIC y luego compilábamos los programas COBOL (poner disco del compilador, ejecutar, sacar disco y poner el del fuente .COB)… :O
Teníamos unos profesores “vejetes” para las materias “antiguas”, uno era no se qué de IBM o alguna de esas, pero para las materias mas nuevas (BASIC, lógica y esas) ya eran becarios del mismo instituto, o sea que excepto algunos profes el nivel no era muy alto. Y nos enseñaron RPG, COBOL, FORTHRAN, esos procesos de cinta maestra, cinta de actualizacion y procesos padres-hijos juasss… cuantos recuerdos que he tenido con tus relatos!!
Aunque yo odiaba ese mundillo de RPG y COBOL, a mi me gustaba el Assembler, Pascal, programación gráfica… quería hacer videojuegos así que todo ese fastidio de aplicaciones de gestión bancaria y económica era una tortura!!
Espero tus próximos artículos con impaciencia
@Kujaku: Sí, ya he estado en tu “nave templaria” viendo los excelentes artículos que allí tienes… ¿No será tu segundo nombre “Het Masteen”, por un casual? Ya sabes, si ves que meto la zarpa en algo, me lo dices: uno tiene buena memoria, pero con tanto producto y tanta sigla, a veces me hago un lío…
@josepzin: ¿Todos los artículos, seguidos? Te habrás tomado una aspirina… Porque, como cuando me pongo a escribir no sé parar, me salen largos,pero largos… Me alegro de que te gusten. Intentaremos que siga así en los que quedan…
Saludos a todos, y gracias por comentar
Mac, ¿podrías dedicar alguna entrada a la bases de datos jerárquicas?
Como bien dices, de eso apenas se enseña ahora. Que yo sepa sólo las nombran de pasada para decir que hay otros tipos de BBDD aparte de las relacionales. Pero aparte de eso los gráficos que ponen para ilustrarlas recuerdan a los árboles que se crean cuando aprendes a usar los punteros, o los objetos de java.
¿Cual es el secreto de su eficiencia para tratar tales volúmenes de datos? ¿punteros en vez de relaciones entre claves?
De veras que me has dejado intrigado (por variar
@joel: Ya está en el horno un artículo sobre la historia de las bases de datos (dos artículos: uno de las bases de datos HASTA que aparecieron las relacionales, y otro, del comienzo de las relacionales). Pero no voy a entrar demasiado en temas técnicos.
Á tu pregunta, la respuesta es sí: mantienen pointers directamente entre cada segmento o registro; una vez leído un registro (normalmente por clave: dame el segmento padre con clave = aaaaa), le vas marcando la navegación, por ejemplo: dame ahora el primer hijo del tipo A; luego dame un hijo de tipo B con clave ‘bbbb’, luego inserta un hijo de tipo C después del último hijo de este tipo que tenga, etc).
IMS mantiene cinco tipos de índices: Phisical Child First y Phisical Child Last (pointers al primero y último hijo de cada tipo); Phisical Parent Pointer (pointer que en cada hijo apunta a su padre directo); Phisical Twin Forward y Phisical Twin Backward (pointers a los gemelos-segmentos del mismo tipo-siguiente y anterior). No todos son obligatorios, algunos sí (el PCF y el PTF lo son). Y te extrañará lo de “Phisical” de los nombres de los pointers: es que IMS permite crear bases de datos lógicas, que cambian la estructura lógica de una BD Física… no entro, pero es fascinante.
Luego, están las Bases de Datos de indices invertidos (Adabas es la más conocida), donde se guardan todos los valores posibles de cada campo (de los que tú decides, claro) con una lista de pointers apuntando a los sitios físicos donde ocurren estos valores. Las queries son resueltas con los índices, y sólo se accede a los registros que cumplan tener los valores pedidos.
Hay información en la red: IBM publica y tiene accesible en la red una cosa llamada “redbooks” donde tiene información técnica de alta calidad sobre todos sus productos; seguro que encuentras información de IMS a punta de pala (y de CICS, y de z/OS, y de DB2…).
Espero que te sirva,
Saludos, Mac
sin palabras, extenso y detallado tu artículo. Me pareció muy bueno. Espero que continues escribiendo mucho tiempo.
Dos palabras Im Presionante, en serio muy bueno, llevo trabajando 2 años como planificador en un sistema OS/390, y no he encontrado mejor documento historico de la evolucion de este gran sistema y contado con este aire de melancolia lo hace mejor, si cabe, en serio me quito el sombrero.
Estimados. recomiendo la lectura especialmente a los nuevos ingenieros. en Santa Fe Argentina sigo utilizando casi todo lo que comentas en un nuevito Z OS, con tiempos de respuesta que son la envidia de todas las novedades que siguen trayendo. Saludos de otro dinosaurio.
Muy interesante! Yo también creo que el editor de ISPF es de los mejores que he conocido, y mira que también he conocido varios y modernos, pero ese es sencillamente genial.
En mi trabajo, todavía lo hacemos como tu describes, y el S0C7 es algo común, si un fallo tonto, pero quieras que no común, jejeje
Estoy de acuerdo, ISPF es lo mejor, y el 0C7 y el ABEND ASRA, lo peor. Una característica también en la época de los 80 eran los nombres: Nuestros códigos de usuario se formaban con acrónimos de los nombres reales, así, surgían usuarios como FRANGUE, SANAYA, MAVEGA… que al final hemos adoptado como apodos en la vida real. Y los nombres que dábamos (y damos) a los programas eran muy típicos: RAVOCLI, RAJOGEN, RAARDIG… Nada de paquetes java ni nombres largos o en inglés. Hay que apañarse con 7 caracteres. Mackluskey, me has enganchado a esta serie. Gracias.
ERRATA:
Cuando dices: ” Por cierto, esta vez la primera vez que el mantenimiento…” debe decir, yo creo ” Por cierto, esta ES la primera vez que el mantenimiento “
Por otra parte, echo de menos los enlaces a la siguiente entrada al finalizar la acutal. Vamos, un mero “GOTO”
“En la Tierra, en el siglo XX todavía se utilizaba el dinero” (Capitán James T. Kirk). Impagable tu esfuerzo en compartir tus conocimientos, Mac. Gracias por tu altruismo
@Venger: Gracias por avisar de la errata… pero se va a quedar, de momento… hace mucho tiempo ya desde la publicación del artículo y no merece la pena andar modificándolo.
En cuanto a los enlaces al siguiente artículo, sí que están (al menos en casi todos). En éste, por ejemplo, lo tienes al final, cuando dice que…
“El próximo episodio lo dedicaré a contaros qué es eso de la Programación Estructurada, como ya amenacé antes.” El enlace lleva al siguiente capítulo, y así en todos (o, al menos, en casi todos).
Saludos
Gracias por esta serie de artículos para todos los que conocimos los ordenadores ya en la época de la microinformática. Las fotos que has puesto ilustran bastante bien cómo eran los ordenadores de la época aunque es verdad que cuesta mucho encontrar fotos de equipos de entonces que tengan buena calidad. Dejo un par de vídeos en donde puede verse cómo era el entorno de computadoras de la época en los 70 y 80: Un vídeo de formación sobre el uso del centro de computadores de la AT&T de 1973 y un vídeo explicando UNIX de AT&T del año 82 (en aquella época muchos conocimos el spectrum): https://www.youtube.com/watch?v=HMYiktO0D64 https://www.youtube.com/watch?v=tc4ROCJYbm0
{ 5 } Trackbacks
Historia de un Viejo Informático. El método de trabajo en los ochenta…
Otra nueva entrega de esta serie de artículos….
[...] http://eltamiz.com/elcedazo/2009/03/09/historia-de-un-viejo-informatico-el-metodo-de-trabajo-en-los-… [...]
[...] » noticia original [...]
La banca de los 80…
Hacía tiempo que no recomendaba lectura. Últimamente la blogocosa es sosa — más si cabe — y cuesta encontrar sitios con temas que no hablen de revoluciones digitales, web 2.0 y esas cosas que cada día me aburren más.
Vía enlace hací……
[...] trabajo informático en la banca durante los años 80 parece que ha pasado una vida desde [...]
Escribe un comentario