
En la entrada anterior terminamos el repaso a los acontecimientos que nos llevaron a inventar el concepto de Data Warehouse, así como las diferentes tecnologías involucradas, y cómo por arte de magia todas estas técnicas recibieron el muy comercial apelativo de Business Intelligence.
Y vimos cómo estos Sistemas eran (y son) utilizados para generar informes variopintos sobre cosas sucedidas en el devenir de la empresa (los famosos Hechos de Negocio). Los usuarios finales solicitan cualquier información que se les ocurre sobre la marcha, en base a las necesidades de cada momento (o sea, lo que en la jerga se llaman queries ad hoc), y el Sistema responde con la información solicitada en un tiempo razonable (segundos, minutos, horas, días… dependiendo de la complejidad de la consulta y de su prioridad).
Todo esto está muy bien, y abre a los usuarios de negocio una enorme ventana a la información que tenemos almacenada en nuestros sistemas. Pero no es bastante… nunca es bastante. Qué forma de ser la nuestra, que nunca estamos conformes con lo que tenemos: ¡siempre queremos más! No se trata sólo de obtener información, en completos listados con bonitas gráficas… se trata de que esa información sirva para algo. Se trata, en definitiva, de convertir la Información en Conocimiento. Es ese conocimiento el que permite a los gestores de la empresa interiorizar situaciones, sacar conclusiones y, por fin, tomar las decisiones adecuadas para mejorar el comportamiento de la empresa. O así debería ser, al menos.
En una palabra, no sólo hay que poder consultar la información y navegar por ella… Hay que encontrar las íntimas relaciones de los datos que explican muchos hechos de negocio, buscar nichos desconocidos o no explotados para abrir nuevos negocios o mejorar los existentes… De todo eso tratará esta entrada, de todas esas técnicas que reciben el muy comercial y, desde mi modesto punto de vista, poco apropiado nombre de Data Mining.
Repito lo que siempre repito: esto no es ninguna crónica oficial de nada. Contaré lo que yo he visto, aprendido e inferido de mis escasas intervenciones en proyectos de Data Mining; existe muchísima información sobre el tema en la red, pues es uno de los puntos calientes actuales en la profesión, y lo que yo cuente aquí no tiene por qué coincidir con lo que dice la historia oficial… ¡qué se le va a hacer! Ya lo decía Eduardo Marquina, en su obra “En Flandes se ha puesto el sol”: España y yo somos así, señora…
La serie tiene ya una veintena larga de artículos. Aquí tenéis el enlace donde encontraréis todos ellos.
Efectivamente, no cabe la menor duda de que pedir cualquier información que se nos ocurra a nuestro Data Warehouse, y que éste conteste de forma fiable y en un tiempo adecuado, es una enorme ventaja competitiva… pero no basta.
Un ejemplo muy, muy conocido (aunque falso: es una leyenda urbana como una casa, pero sirve para ejemplarizar el tema) servirá para fijar las ideas:
En los años 80, WalMart, la mayor compañía de distribución minorista del mundo de entonces y de ahora, compró e instaló uno de los primeros Teradatas, para averiguar cosas acerca de su negocio. Y al cabo de poco tiempo empezó a circular por doquier la historia siguiente:
“WalMart había descubierto que, los sábados por la tarde, se producía un interesante hecho de negocio: había muchos clientes que compraban simultáneamente pañales y cerveza…”. Había versiones que iban más allá, y aseguraban que esos clientes eran, además, hombres.

Pañales y Cerveza... ¡una mezcla explosiva!
La consecuencia que se sacaba es que WalMart había identificado un nicho de mercado donde había un conjunto considerable de personas (u hombres, según la versión) que compraban simultáneamente dos productos aparentemente muy poco relacionados entre sí: pañales (para bebés, supongo) y cerveza (para bebérsela, me imagino). Y WalMart había sacado mucho partido a tal conocimiento… porque además, en la historieta se interpretaba la razón de tal comportamiento: hombres con hijos pequeños (en edad de llevar pañales), y sin posibilidad de salir por la noche, pues tienen que cuidar a su hijito, se proveen de cervezas en abundancia para alegrarse la noche, seguramente viendo algún partido de algún deporte por la tele con algunos amigotes.
Bueno, esto no ocurrió jamás. Es una leyenda urbana, como antes dije. Pero durante muchos años nos estuvieron martilleando docenas de consultores (no exagero, de veras) con el maravilloso ejemplo y las posibilidades que encierra poder descubrir cosas igual de interesantes. Y todos nos poníamos bizcos de placer pensando lo que se podría hacer con semejante conocimiento… o mejor, lo que yo, o mi empresa, podríamos hacer con semejante conocimiento. No obstante ser mentira, voy a utilizar el conocido ejemplo para intentar explicar qué es eso del Data Mining, dado lo sencillo de entender que es, hablando a mi rústica manera sobre los conceptos más importantes que hay ahí enterrados.
En primer lugar, sobre la propia definición de la disciplina del Data Mining. Muchas definiciones similares, pero distintas, podréis encontrar sobre qué es eso de la Minería de Datos. A mí la que más me gusta de las que han caído en mis manos (ignoro la fuente, sinceramente) es: “Data Mining es el Proceso de descubrimiento mediante métodos automáticos, sobre las Bases de Datos, de Conocimiento valioso y no evidente que se encuentra enterrado en la semántica intrínseca de los datos”.
En nuestro manido ejemplo, queda claro que el Conocimiento obtenido es No Evidente (no creo que nadie en sus cabales imaginara siquiera tal relación entre cerveza y pañales); en cuanto a lo de Valioso… bueno, le concederemos el beneficio de la duda. Lo que es también claro es que es un descubrimiento que ha debido de hacerse de forma automática, o sea, un programa informático, con infinita paciencia (o, mejor, ejecutando un buen algoritmo de descubrimiento) ha ido probando combinaciones improbables hasta encontrar una que da un resultado interesante… no me imagino yo a un sesudo analista probando posibles combinaciones una tras una: ¿Leche y Galletas? ¿Lejía y Comida Kosher? ¿Vino blanco y Pimienta? ¿…? Las combinaciones son innumerables, hasta llegar a… ¿Pañales y Cerveza?
En segundo lugar, sobre la utilidad en sí del descubrimiento. No tengo ni la menor idea de qué podría hacer WalMart para convertir un conocimiento tan privilegiado en una mejora sustancial de su negocio, es decir, más venta (que es como mejoran su negocio las grandes compañías comerciales). Quizá hacer una promoción “Compre una docena de pañales y le regalamos una birrita” o, mejor aún: “Comprando dos docenas de cervezas le regalamos dos pañales King-Size, que si su hijo aún no los gasta… ya los gastará”. O poniendo juntos los Pañales con las Cervezas, en la misma sección del supermercado, para que los pocos desmemoriados que compran una cosa no se olviden de llevarse también la otra. Para mí que, de ser cierta, esta relación Pañales-Cerveza no es muy útil para aumentar el negocio, pero Doctores tiene la Iglesia…
Ojo, que aunque en este ejemplo se ve malamente qué utilidad inmediata puede tener para el mejorar el negocio, puede haber otros casos en que un descubrimiento de este estilo sí que puede tener una enorme utilidad, bien aumentando el negocio, bien reduciendo costes, reduciendo riesgos, etc.
En tercer lugar, sobre la inferencia de por qué se produce ese hecho específico de negocio. Resulta que está claro, clarísimo, cristalino, que eran hombres y jóvenes los que compran la cerveza para ponerse ciegos mientras ven el partido de los Bulls contra los Sixers, mientras el niño pequeño berrea y su madre le cuida y le cambia los pañales ¿no? Pues no. Eso es un estereotipo que no tiene por qué ser verdad… A ver por qué extraña razón eso tiene que ser así y no es de cualquier otra manera. La realidad pura y dura es que el descubrimiento (si hubiera sido real, que ya sabéis que no lo fue) nos dice que hay clientes que compran simultáneamente pañales y cervezas los sábados por la tarde… y Punto. Otras interpretaciones sin datos que las avalen pueden conducir mayormente a monumentales errores en las decisiones tomadas.
Y en cuarto y último lugar, sobre el propio hecho de que un tan importante y trascendental descubrimiento para WalMart fuera tan conocido en todo el resto del mundo mundial… Si yo fuera WalMart, y conociera algo realmente interesante sobre el comportamiento de mis clientes, que puedo aprovechar para, inmediatamente, generar mayores ventas o beneficios donde, además, cualquier estrategia que ponga en marcha para explotar lo descubierto es fácilmente replicable por mis competidores… lo último que haría sería comunicarlo a los cuatro vientos. Me callaría como un muerto y explotaría el filón todo lo posible, esperando que los buitres de mis competidores no se enteren (o que lo hagan lo más tarde posible) ni de la existencia en sí del nicho, ni de mis acciones para explotarlo.
.
Creo que después de desmenuzar un poco lo que hay detrás de una adquisición de conocimiento de este tipo, quizá haya quedado más claro qué es y para qué sirve eso del Data Mining.

Minería de Diamantes a cielo abierto, en Sierra Leona
Nombre que, por cierto, a mí me parece espantoso. A mí, Minería de Datos me evoca un trabajo penoso, sucio, costoso, con cierto riesgo, para arrancar a la montaña de datos los escasos diamantes de gran valor que están ocultos en su interior… y es una descripción muy adecuada de lo que es el trabajo de Descubrimiento. Pero no es muy comercial, puesto que el principal objetivo de la Minería de Datos no es el propio proceso de cavar y cavar, sino entender realmente el Significado oculto de los datos.
Yo tengo una teoría estúpida de por qué ese nombrecito… Ahí va (no ibais a esperar que, a estas alturas, me callara, ¿no?).
“Alguien, inglés o estadounidense, por supuesto, definió esta actividad en sus comienzos y la bautizó con el nombre más lógico y adecuado, a saber: “Data Meaning”, dado que lo que queremos es conocer el significado de la información… Se lo contó a algún técnico o ejecutivo español, y el hombre, con sus escasos conocimientos de anglosajón, apuntó en sus apuntes “Data Mining”… total, como suena igual… (¡a quién se le ocurriría que en inglés la i se pronuncie ai, y que el diptongo ea se pronuncie i… a veces!). Al llegar a España, apuntó el término en alguna presentación, la presentación cayó finalmente en manos de algún genio del marketing, la cosa hizo gracia… y la disciplina fue finalmente rebautizada”.
Fin de mi estúpida teoría. Posible, ¿no?
.
Fueron los Departamentos de Marketing de todo tipo de empresas los que empezaron a demandar un tipo de conocimiento que no estaba disponible. Si os acordáis de mis cuitas con el responsable de aquel banco, hace treinta años o más, que os conté en esta entrada los Departamentos de Marketing tenían muy poco soporte de Aplicaciones Informáticas… y poco que hacer, además. Tomaban información de la Base de Datos de Clientes, con los criterios que buenamente se les ocurrían, pero no eran capaces ni siquiera de poder averiguar el alcance de sus campañas publicitarias… Me explico:
Sea un gran Banco, que hace una campaña para ofrecer un nuevo producto, digamos una Tarjeta de Crédito, cuando en España todo el mundo pagaba en pesetas contantes y sonantes. Para ello, utiliza técnicas de marketing mix, es decir, varios medios (canales, en la jerga) para publicitar el nuevo y maravilloso producto. Anuncios en Televisión, Anuncios a página completa, o Insertos en Prensa, Cuñas en Radio, Vallas Publicitarias… y además hace un envío de folletos a los domicilios de sus clientes, a todos ellos, o sólo a unos pocos, los que a priori van a ser más proclives a tan novedoso producto financiero. Y además, se instruye a la fuerza comercial para que ofrezca y venda el producto a todo cliente que pise una oficina. Se conceden entrevistas a periodistas, que se publican en los diarios más influyentes… un despliegue de cuidado, vaya.
La campaña sigue su curso, y al cabo de dos meses, o tres, cuando se decida, se hace balance. Dos cosas pueden ocurrir:
1 La campaña fue todo un éxito. Todo el mundo se congratula: el Producto Diseñado es magnífico, y el momento elegido para su lanzamiento, perfecto; la Campaña publicitaria ha sido formidable, incluyendo la elección de la actriz de moda apropiada para convencernos de lo útil del invento; el comportamiento de la fuerza comercial ha sido extraordinario, consiguiendo altísimas cotas de aceptación del producto entre la clientela; el folleto estaba bien diseñado y se ha enviado exactamente a los clientes más interesados… Vamos, que el éxito ha sido gracias a todos y cada uno de los intervinientes en exclusiva. Y como la cosa ha ido bien, pues nada, parabienes para todos y listo.
La realidad pura y dura es que nadie sabe las causas reales por las que la campaña haya sido un éxito, por lo que es muy difícil capitalizar el conocimiento necesario para poder repetirlo en un futuro, con otro producto.

Ratas, huyendo por las troneras
2 La campaña resultó un fracaso. No se llega ni de lejos a los objetivos marcados. La imagen más parecida que me viene a las mientes para representar la situación es la de las ratas huyendo por las troneras antes de que el barco naufrague… Este es uno de esos momentos en que todo el mundo asegura aquéllo tan español de “Lo mío está bien” y culpa al de al lado, a todos los de al lado, del fracaso de la campaña. La campaña ha fracasado porque el producto no estaba bien diseñado, porque se ha lanzado en un momento poco idóneo, los anuncios de televisión eran chabacanos, o demasiado sofisticados, o el actor estaba mal elegido, con su carita de niño bueno, los comerciales en las oficinas han pasado del tema… y así todo.
La realidad es que las campañas a veces son un éxito y a veces fracasan, no hay quien tenga siempre la bola de cristal en perfecto estado de funcionamiento… lo realmente importante es averiguar las razones del éxito o del fracaso, para repetirlas en el futuro, las primeras, o evitarlas, las segundas, no convertir la campaña en una carrera a ver quién ha hecho mejor su trabajo, en el primer caso, o quién no tiene la culpa, en el segundo.
Por aquellos años se comenzó a poner de moda un nuevo concepto: el micromarketing. Es decir: dirigir a cada cliente las ofertas de productos en que esté interesado, evitando costosas campañas masivas de escasa penetración y alto costo. No tiene sentido intentar colocar un Fondo de Inversión a un cliente que no nos paga la Hipoteca. Y yo he visto casos como éste, o peores… Pero no se trata sólo de cosas tan sencillas como esta tontería, para eso no hace falta Data Mining de ningún tipo, sólo un poco de sentido común.
Lo interesante de usar técnicas de Minería de Datos aplicadas al micromarketing es que permiten localizar nichos interesantes y completamente desconocidos previamente. Pongamos un ejemplo sencillo: Vamos a lanzar un Fondo de Inversión, y se lo ofrecemos selectivamente a un grupo de clientes que nos parece que pueden estar interesados, sea como fuere que tengamos este convencimiento.
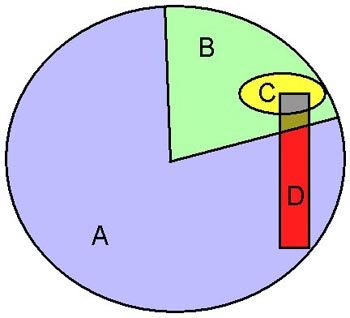
Grupos de Clientes ante una Campaña de Marketing
En el círculo de la imagen de aquí al ladito vemos un esquema de esa campaña. Dentro del círculo tenemos a todos los clientes del Banco susceptibles de recibir la oferta (hemos eliminado los que nos deben dinero y cosas así). De ellos hemos seleccionado a más o menos la cuarta parte, el segmento circular con forma de quesito de la derecha, y a ellos, y sólo ellos, nos hemos dirigido para ofertarles nuestro magnífico producto. Así que, a los clientes del grupo A (los azules) no les hemos ofrecido nada, así que nada pueden comprarnos, mientras que al grupo B (los verdes) sí que nos hemos dirigido, por carta, llamando por teléfono, o como sea.
Miramos ahora a los que sí han comprado el producto (donde hemos tenido éxito), y resulta que es el grupito C (el amarillo). Supongamos que ese grupo representa el 6% de todos los clientes del grupo B (los receptores). Ese 6% puede ser bueno o no, depende, pero no se trata de eso, sino de aprender para conocer a nuestros clientes…
Empezamos, pues, a estudiar qué ha pasado en la campaña. Y tras mucho cavilar, descubrimos que hay un grupo de clientes D (los rojos, eeh, perdón, el grupo color rojo) que son los que tienen una Hipoteca de Segunda Vivienda, a algunos de los cuales les incluimos en su día en la campaña, y a otros no. Y vemos que, de todos los clientes de ese grupo D a los que sí les hemos ofrecido el Fondo (la intersección del grupo D con el grupo B), resulta que hay un 42% de clientes que sí lo han contratado (el grupito marcado en gris, que es la intersección de los grupos B, C y D) mientras que el 58% restante, no lo han hecho (el grupito marcado en verde oscuro y amarronado).
Como sólo el 6% de todos los clientes a los que se lo hemos ofrecido lo han contratado, parece que ese nicho concreto (Clientes con Hipoteca de Segunda Vivienda) son mucho más proclives, exactamente siete veces más (el 42% contra el 6%), que nuestro cliente medio. Si lo hubiésemos sabido en el momento de diseñar la campaña, claro que hubiéramos hecho la oferta a todos los clientes de ese grupo tan particular… pero no lo sabíamos. Lo importante no es mesarse los cabellos por la oportunidad perdida, eso es una pérdida de tiempo. Lo importante es aprender cómo son nuestros clientes, para que, cuando tengamos que hacer un nuevo ofrecimiento de otro producto de inversión, como un depósito o un nuevo fondo, seleccionemos en primer lugar a todos esos clientes del Grupo D, sin desechar a ninguno, que parecen muy interesados en estas ofertas… Por cierto, esto que estoy haciendo se llama Segmentar, y hay varias técnicas entre todas las de Data Mining orientadas a obtener segmentos de datos.
Todas las empresas comerciales se lanzaron, a mediados y finales de los noventa, a explorar estas nuevas posibilidades, con mejor o peor éxito. Pero hubo un sector de empresas que lo hicieron con muchísimo más ahínco que ninguna: las “Telcos” (nombre genérico que reciben las grandes empresas de telefonía y comunicaciones), debido no sólo a su potencia financiera, sino al hecho de que esos años se estaba produciendo una brutal desregulación en el mercado de las telecomunicaciones en todo el mundo, abriendo los tradicionales monopolios nacionales a la competencia… Telecom Italia, Deutsche Telekom, France Telecom, British Telecom… y Telefónica, claro.
Todas ellas tuvieron, de grado o por fuerza, que compartir sus monopolizados mercados con nuevas empresas, que irrumpieron cual elefante en cacharrería, con fortísimas inversiones que había que amortizar. Y las que ya estaban, procuraban conservar a toda costa sus clientes… perdón, sus abonados, que fue más o menos entonces cuando los abonados nos fuimos convirtiendo en clientes… ¡Qué buenos tiempos, donde llamabas y te atendía una señorita (a veces un caballero, pero pocas) que te solucionaba tus problemas!, en vez de tener que tener que entenderte con una máquina parlante que está entrenada para marearte, aburrirte y que cuelgues, eso sí, habiendo llamado a un 902… En fin.
Y no sólo telefónicas varias entraron en el mundo de la segmentación y el micromarketing, toda empresa que se preciara de todos los sectores entraron a mejorar su Sistema Comercial. Bancos, Aseguradoras, Distribuidoras, Fabricantes… Fue cuando comenzamos a oír hablar de los sistemas de CRM, Database Marketing…
Empezaron a llegar noticias de éxitos, debidamente aireados por fabricantes y consultores… por ejemplo, una Compañía de Seguros británica encontró un nicho de clientes excepcionalmente rentable: estudiado, resulta que se trataba de coleccionistas de coches clásicos (se ve que en el Reino Unido había bastantes de estos).

Quien tiene un Triumph del 59, lo cuida como a un hijo
Son, efectivamente, clientes que apenas circulan con sus preciados juguetes, y que los cuidan y miman más que Fernando Alonso a su Renault… y sin embargo los tienen todos asegurados. Y esta compañía sí que encontró cómo rentabilizar su descubrimiento: preparó una póliza especial para coleccionistas, con mejores condiciones que las habituales, y utilizó a los Royal Automobile Clubs de todo el país para ofrecérsela a todos los coleccionistas… robándoselos en buena medida a la competencia, y por tanto, incrementando su negocio y sus márgenes… una temporada, puesto que el resto de competidores reaccionaron al cabo de poco tiempo, pero ya sabéis que quien da primero, da dos veces.
Buena parte de las ofertas extrañas de las telefónicas de todo pelaje que nos hacen día sí, día también, se basan en el descubrimiento de nichos de mercado, que procuran aprovechar antes que la competencia los descubra. Y así con casi todo.
Todos ellos permitían controlar las diferentes campañas publicitarias, por fases, con la selección de los clientes más propicios… sólo que esto último es, en buena medida, mentira. Lo de seleccionar clientes propicios no lo puede hacer automágicamente una herramienta solita, sin la colaboración de un humano que se conozca el percal: lo más importante para poder hacer buenos estudios de Data Mining siguen siendo los paisanos… Volveré a esto más adelante.
Las técnicas en que se basa la Minería de Datos son, con alguna excepción, conocidas desde hace mucho tiempo, y se basan tanto en la Estadística como en las Ciencias de la Computación y en la Inteligencia Artificial. Sin embargo, sólo el advenimiento de potentes máquinas de proceso en paralelo permitió de verdad realizar estudios sobre una cantidad considerable de datos… Así, a bote pronto, podemos citar entre sus técnicas más utilizadas el Análisis Factorial, la Regresión Lineal o Logística, Asociación, Segmentación (Clustering), Análisis Chaid, Predicción (Forecasting)… y varias más.
No voy a describir ni detallar ninguna de estas técnicas… podéis respirar tranquilos; siendo como es uno de los hot-topics del momento, hay en la red toda la información que deseéis, mucho mejor estructurada y detallada de lo que este pobre informático vejestorio y lenguaraz pudiera hacer, así que… ésa es otra historia y será contada en otro momento, o mejor, por otro.
Lo que sí cambió a finales de los noventa fue la posibilidad real de poder aplicar cualquiera de estas técnicas a grandes volúmenes de información, gracias a los nuevos servidores de gran potencia de cálculo y capacidad de almacenamiento, así como nuevas implementaciones de algoritmos conocidos para aprovechar el paralelismo ofrecido por la tecnología. Si a eso le añadimos una mucho mayor capacidad de visualización de los resultados, tanto de forma tabular como gráfica, y el que los datos origen para hacer el estudio, habitualmente contenidos en el Data Warehouse, tenían un formato mucho más normalizado y unificado que cuando estaban en sus Bases de Datos originales, el Data Mining se hizo, por fin, posible.
Dos productos existían ya a finales de los noventa con fantásticas capacidades estadísticas, pues ambos nacieron como programas especializados en la resolución de problemas estadísticos, y ellos fueron de los primeros que se apuntaron al carro del Data Mining, expandiendo sus ya bien estructuradas suites para cubrir aquellas áreas o técnicas que no lo estaban.
Uno de estos productos fue SAS, de excelente calidad y poderosos módulos estadísticos, y que pronto unificó inteligentemente todos los módulos necesarios en el SAS Enterprise Miner, producto caro y complicado de usar, pero potentísimo para tratar con volúmenes muy elevados de datos. El otro fue SPSS, muy bien posicionado en ambientes académicos y en algunos sectores clave, fundamentalmente el sanitario.
Me contaron que el Institut Català de la Salut (encargado de la Sanidad Pública en Cataluña) se enfrentó a un problema sanitario realmente curioso… y preocupante: la incidencia de determinadas alergias en la ciudad de Barcelona tenía unos picos de incidencia elevadísimos en ciertos momentos del año, que no respondían a ningún patrón conocido (germinación de arizónica o gramíneas, etc), y que se repartía de forma irregular a lo largo del año; además, los brotes eran muy virulentos y afectaban a muchas personas simultáneamente, que debían recibir atención médica y ser, en muchos casos, dadas de baja por enfermedad. Aparentemente, sólo una causa externa podía justificar esos cuadros alérgicos, pero… ¿cuál?
Varios investigadores se pusieron manos a la obra (incidentalmente, usando SPSS) hasta que varios meses después un genio encontró por fin una correlación casi perfecta entre las descargas de soja en el puerto de Barcelona y, un par de días después, la aparición de los brotes.

Descarga de Grano. Obsérvese la nube de polvo que se produce.
Resulta que los buques de transporte de grano lo llevan a granel, en sus bodegas, y para descargarlo se empleaba un aspirador, o quizá un elevador de granos, que recogía el grano de la bodega y lo llevaba al silo; toda la operación se hacía al aire libre, y generaba un enorme polvo… que se repartía por toda la ciudad y ponía muy malitos a muchos pobres alérgicos. Conocida la causa, fue sencillo poner remedio: cerrar herméticamente los silos para evitar el polvo.
Lo que me extraña es que siga habiendo puertos que descarguen granos de la manera que se puede observar en la foto… pues sí. ¡Obsérvese la polvareda! Los humanos no aprendemos nunca…
Muchos productos de Data Mining aparecieron al calor de la novedad; unos tenían más funciones, otros menos… todos competían por el emergente mercado naciente, y unos tuvieron más éxito que otros… lo de siempre, vaya.
IBM concentró una serie dispersa de algoritmos que había ido desarrollando a lo largo de los años en su Suite Intelligent Miner; hizo alguna venta pero no demasiadas (apenas tenía técnicos en España para implantar la solución), y ahora ha sido incorporado dentro de la propia Base de Datos DB2.
Angoss, Clementine, y otras varias más también tuvieron su momento de gloria… luego llegó la consabida “consolidación del mercado” y la mayoría fueron compradas (como Clementine, que fue comprada por SPSS, por ejemplo) o simplemente desaparecieron. SAS y SPSS son, hoy en día, los vencedores de la guerra del Data Mining… con alguna excepción proveniente del software libre: Weka, creado y mantenido por la universidad neozelandesa de Waikato, es libre y tiene una potencia mediana; es una excelente herramienta, y muy recomendable para comenzar a jugar con el Data Mining.
Pero… la clave son las personas. Por mucho producto atómico que compremos, hay que saber utilizarlo… y eso no es nada, pero nada fácil de encontrar. El perfil adecuado para que alguien haga estudios de Data Mining incluye un excelente conocimiento del negocio, para seleccionar e interpretar la información obtenida. Obviamente, debe conocer las diversas técnicas utilizadas, para qué sirve cada una y cuándo utilizar una u otra, o bien confirmar los hallazgos realizados con una mediante otra diferente… Además, tiene que ser capaz de convertir y manipular datos para adecuarlos al estudio concreto a realizar, categorizando variables continuas, eliminando información irrelevante, etc. En una palabra, que se trata de un perfil dificilísimo de encontrar en cualquier empresa, por grande que sea… pero es que tampoco es nada sencillo encontrar un consultor que cumpla los requisitos.
Y el caso es que, sobre todo a las empresas financieras, no les queda más remedio que encontrar ese perfil, debido a los Acuerdos de Capital de Basilea II…
Ah, claro, que la gran mayoría de vosotros nunca ha oído nada de Basilea, salvo como destino turístico, o quizá sí hayáis oído hablar de “Basilea II” pero no sabéis qué es eso ni para que sirve. Pues nada, aquí estoy yo para explicarlo, si os interesa…

Basilea: Una ciudad preciosa, sede del Banco Internacional de Pagos
En la preciosa ciudad suiza de Basilea está el Banco Internacional de Pagos, y allí se cocinan muchas de las regulaciones y normas que afectan a la Banca Internacional. En el año 1988 se firmó el Acuerdo de Capital de Basilea, el primero, que entre otras cosas obligaba a los Bancos a realizar provisiones para garantizar sus riesgos, es decir, la posibilidad de que sus créditos y préstamos (que no son lo mismo) resulten impagados. Esas provisiones consisten en que tienen que depositar un porcentaje de la cantidad prestada en el Banco Regulador (en España, el Banco de España), sin interés ninguno, o con muy bajo interés. El porcentaje que representa estas provisiones tiene que ver con el tipo de riesgo; si mi vieja memoria no me engaña, para crédito hipotecario, el 2,25%; para riesgo a empresas y particulares no hipotecario, el 5% y para crédito al consumo (sobre todo, tarjetas de crédito), el 8%.
Esas provisiones aseguran que, en caso de que una parte de los créditos concedidos por ese Banco resulten morosos, no afecte a la solvencia del Banco y no se lleve los dineros de sus depositantes (de todos modos, ya hemos visto que eso tampoco pasa: si un Banco tiene problemas, papá Estado, o sea, nosotros, los contribuyentes, acudimos a salvarlo). Basilea I sirvió para mejorar la solvencia de la Banca Mundial, pero ya a principios de los dosmiles estaba claro que, por un lado, estaban apareciendo nuevos instrumentos financieros “sofisticados” (léase “pensados para limpiarte la pasta sin que te des ni cuenta”, que yo he picado en un par de esos), que, además, se escapaban por los flecos que Basilea I dejaba abiertos. Y además, en un ciclo expansivo de la economía, tras el fiasco de la burbuja puntocom de la que hablaremos en la próxima entrada, esos porcentajes se antojaban altísimos… para la propia banca, claro está. ¡Hombre, por dios! Con lo bien que se selecciona el riesgo, un 2,25% de provisiones es altísimo, a quién se le ocurre…
La solución: Los Acuerdos de Capital de Basilea II, firmados en 2004, y que constan de un montón de regulaciones y recomendaciones, pero que, mayormente, consiste en que los Bancos establezcan “sofisticados” sistemas de control del riesgo, basados en técnicas estadísticas y de tendencia de extraordinaria solvencia y exactitud, que ellos mismos definen… no, esperad, que es peor: cada banco define su propio sistema estadístico “sofisticado” de valoración del riesgo, y lo pone en marcha y lo usa. Básicamente mide dos parámetros: la probabilidad de “default” (impago) de un cierto crédito a lo largo del tiempo, y el monto esperado de parné que, en caso de default, va a dejar a deber el prestatario.

Gestión de Riesgos: Como un Castillo de Naipes.
Los Bancos reguladores (en España, el Banco de España) revisan que el Banco ha implantado un “sofisticado” sistema basado en la estadística, y que lo cumple a rajatabla… y entonces, las provisiones que debe realizar el Banco o Caja de Ahorros se reducen sustancialmente… hasta más de la mitad, según los casos. Eso representa muchísimos millones. Y mientras tanto, mientras no tengan implantados los “sofisticados” Sistemas de Control Crediticio… siguen funcionando las elevadas provisiones antiguas. Así que todos los Bancos y Entidades Financieras se adhirieron entusiásticamente a Basilea II, lo que les obligó a entrar de lleno en el proceloso mundo de la estadística o del Data Mining, dando el espaldarazo definitivo a este tipo de productos.
Y no me preguntéis qué opino personalmente de Basilea II, y de que sean los propios bancos los que se “autorregulen” para conceder riesgos; no hay más que ver cómo han acabado la mayoría de “autorregulados” en los últimos meses para constatar la eficacia de la “autorregulación” financiera, pero ésa es otra historia y será contada en otro momento. La cruda realidad es que antes de Basilea II, cualquier inspector del Banco de España, en un día y con una simple hoja electrónica, era capaz de auditar todos los parámetros básicos de una entidad financiera. Ahora, ni en un mes, y además necesita conocimientos estadísticos y de Data Mining al alcance de muy pocos (son inspectores financieros, no estadísticos). Veremos cómo acaba esta historia…
En fin, nominalmente muchas empresas tienen Sistemas y Departamentos dedicados a realizar estudios de Data Mining. A los Bancos, si quieren tener las ventajas innegables que Basilea II les ofrece, no les queda más remedio que tener uno asociado al departamento de Riesgos. Si no, no cuela, y no pueden beneficiarse de las ventajas que les ofrece el nuevo Acuerdo. Muchísimas empresas comerciales, que dedican grandes cantidades de dinero al marketing, también hacen estudios más o menos sistemáticos, aunque lo más normal es que estas funciones estén embebidas en los Sistemas CRM que tengan instalados.
Ignoro su uso real… pero es que estoy convencido de que las empresas que lo usen de verdad y obtengan resultados interesantes para su negocio, se los callarán como un muerto (yo me los callaría; si yo tengo una empresa dedicada a la venta de zapatos y descubro que los clientes que tienen más de dos pies compran el doble de zapatos al año que los que tienen dos pies o menos, haría una campaña para explotar el nicho descubierto y sería como una tumba, para que la competencia no se entere y me pise, nunca mejor dicho, el nicho).

La ex-mina de diamantes de Kimberley, hoy
…Y así hasta que el dichoso nicho esté completamente explotado, y haya extraído todos los diamantes, como en la famosa mina de diamantes de Kimberley, en Sudáfrica, que, explotada durante cincuenta años (desde 1866 hasta 1914), de ella sólo queda un agujero inmenso lleno de agua… y sin ningún diamante dentro.
Así que la información que hay en el mercado sobre éxitos en la aplicación del Data Mining es escasa, y sobre todo, poco fiable. No me creería yo mucho los “casos de éxito” que nos presentan los consultores para demostrarnos lo bien que hacen las cosas.
La clave, repito, son las personas. Algunos consultores tienen gente muy preparada, qué duda cabe. Pero hay que traspasar el conocimiento a las personas de la empresa. Y desgraciadamente, al menos en España, los destinatarios de dicho conocimiento son poco receptivos. Hay poca formación básica en los responsables de estudios, analistas de negocio, etc, y menos aún en los Directores, para los que una Desviación Típica es… ¡la homosexualidad! (no, no os riáis, que ésta es una anécdota real que yo he oído preguntar a un Director General de Muchas Cosas de una importante compañía manufacturera española).
Se manejan muchísimos datos, cierto, pero el único estadístico que la gente entiende (más o menos) es la media, a veces, sin ponderar siquiera: “el consumo medio de los turistas extranjeros en España es de 94 Euros por día”, por ejemplo. ¿Y ese dato tan sesudo para qué vale? ¡Al menos habría que acompañarlo con la desviación típica! Por ejemplo: “una media de 94 Euros por día con una DT de 78 Euros”, refleja una realidad completamente distinta de si es “94 Euros de media con una DT de 5 Euros”. Con la Desviación Típica, al menos me hago una idea, parcial y con no excesivo valor añadido, pues sería mejor usar más estadísticos, los más descriptivos en cada caso, por ejemplo percentiles, segmentado en los principales grupos… pero ¿sólo con la media? ¿Qué información da eso, para qué podemos usarla? ¡Para nada! En fin…
…Pero, claro, es que nadie entiende ningún estadístico. Yo lo sé: he hecho informes donde he utilizado cuatro estadísticos tontorrones para intentar explicar lo que pasa en algún sitio (mis conocimientos de Estadística de Tercero tampoco dan para más)… y nadie entiende otra cosa más que la media, la dichosa media, y a veces, mal calculada. Pocos saben interpretar un cierto valor de percentil, qué significa, para qué sirve… y eso si no te dicen directamente que “eso de la estadística es una engañifa…” (esto también lo he oído yo con mis propios oídos) y descartan por irrelevante e inicuo todo dato que contenga un estadístico… que sea diferente de la media, claro, la omnipresente y ubicua media.
Tenéis mucho por hacer, jóvenes lectores, si queremos cambiar esto alguna vez. En vuestras manos está; yo no he podido o sabido… y ¡por Tutatis! que lo he intentado, pero se ve que los tiempos no habían llegado. ¡Suerte!
.
En la próxima entrada hablaré, siempre desde mi peculiar punto de vista, de las circunstancias tecnológicas, pero, sobre todo, económicas y comerciales, que dieron origen a la imparable ascensión y tremendo batacazo posterior de mil y una empresas de internet, hablaré de lo que se ha dado en llamar “la burbuja puntocom”, si es que os interesa el tema…
La serie está concluyendo; tened un poco de paciencia con este pobre informático del Cretácico Superior, que pronto haré mutis por el foro, junto con mis colegas los Dinosaurios que se extinguieron justo al final del Cretácico…
Disfrutad de la vida, mientras podáis.

The Historia de un Viejo Informático. El descubrimiento de la Minería… de Datos. by , unless otherwise expressly stated, is licensed under a Creative Commons Attribution-Noncommercial-No Derivative Works 2.5 Spain License.


{ 26 } Comentarios
¡¡¡Tócate los pies!!!, si la estadística les parece una engañifa ¿para qué puñetas se interesan por el data mining, que es precisamente una herramienta estadística?.
¿Y quién ha dicho que les interesa? Lo soportan, sí, no les queda más remedio, pero ¿interesarles?
No te puedes imaginar cómo está el patio, de verdad… ¡me he quedado corto!!
Ahí he tenido suerte, con una profesora de Estadística realmente buena, tanto como profesora como como estadística. Y no veas qué atravesada tenía la media. Más de una vez nos explicó que puestos a dar un único dato en poblaciones muy dispersas es mejor la moda que la media, y siempre ponía de ejemplo el salario medio, esa invención que no le sirve a nadie de nada.
Sé que esto es patético a mis años, pero acabo de tener una revelación al leer eso… ¡gracias!
@Pedro: NO ME LO PUEDO CREER!!! No, el Gran Jefe, no.
Claro que, si yo te digo lo que me parecía a mí qué era la Relatividad antes de leer tu libro… Así que, empatados.
Fijaos, fijaos en la prensa diaria, en la televisión… ¿cuántas veces nos dicen que “el euribor ha bajado tanto y tanto y la hipoteca media bajará 12 euros al mes”? ¿COMORRR? ¿Alguien es capaz de explicar a alguien qué rayos es eso de la “hipoteca media”? ¿Para qué sirve ese dato?, en caso de que sea correcto, que ésa es otra…
En fin. Welcome to MeanLand… aquí no sabemos otra cosa que la media… ¡Y gracias!, que los hay que ni siquiera.
Saludos a todos, incluso a los que no saben lo que es una desviación típica.
No hay nada como escuchar la voz de la experiencia. Te agradezco enormemente que compartas tu conocimiento y tu visión, profesional y personal.
Grande!
Hay otro campo donde está empezando a ponerse de moda esto del Data Mining, que es la explotación de bases de datos científicas. Por ejemplo, en Astronomía en los últimos años disponemos de gigantescas bases de datos con decenas de miles o en ocasiones millones de objetos, cada uno de ellos con decenas o cientos de propiedades. Intentar extraer conocimiento de esa cantidad enorme de información con métodos tradicionales es cada vez más complicado, así que el asunto este de la minería de datos está empezando a sonar cada vez más. Si a eso le unimos otros proyectos como el observatorio virtual (VO), que se supone que tiene que ser como una especie de protocolo para que interactuar con esos datos sea algo más o menos homogéneo, pues parece que del tema este puede acabar saliendo algo interesante, aunque de momento no conozco ningún resultado espectacular (al estilo cervezas y pañales) que se haya obtenido aplicando estas técnicas.
Muy interesante este artículo, Mac. El concepto de minería de datos (¡qué buena paráfrasis de meaning!) se asemeja mucho a la tarea del científico: buscar patrones. Piensa que la naturaleza nos brinda una colosal cantidad de datos, a partir de los cuales debemos encontrar el meaning oculto. Pero lo que no sabemos es si tal significado lo aprehendemos de ella o lo inventamos nosotros…
Bajando un poco de la exosfera, me puse a pensar que el velocísimo avance en modelos de simulación por computadora de situaciones de negocio podría desembocar en la total certidumbre de lo que ahí decías, del conocimiento total de lo que desean y no los clientes, y en función de eso encontrar los patrones que aumenten la productividad de la empresa, aunque el resultado parezca absurdo e incomprensible… ¡¿cervezas y pañales?!
Ah! Y ya que mencionabas la Estadística, recuerdo que cruzki nos tiene esperando con el inicio de su serie… desde hace varios meses. Espero que pronto disponga del tiempo para empezarla.
Un abrazo, Mac.
@lucas: Gracias por tus agudas percepciones. Sí, efectivamente. Corremos el riesgo de pensar que nuestros modelos son perfectos y nos basamos en ellos para casi todo como si fueran el Oráculo de Delfos… Y no.
En toda predicción estadística se deben incorporar al menos dos valores: el error y la confianza. Por ejemplo, se predice el resultado de una votación, y el partido tal tiene una proyección de voto del 30%. ¡ESO NO DICE CASI NADA SOLO! si no va acompañado de la confianza y el error. Por ejemplo, la predicción de voto es de un 30% con un error del 3% y un margen de confianza del 95%. Eso quiere decir que, si se votara cien veces, en 95 de ellas el error no será superior al 3% (o sea, que en realidad la predicción de voto es ENTRE el 27% Y el 33%, cosa que casi nadie dice). Pero es que en las otras 5 veces, el error sería superior. Como sólo se vota una vez, se suele acertar… pero lo que esto quiere decir es que, de media, de cada veinte votaciones, en una de ellas el resultado no se parecerá ni por el forro a cualquier sesuda predicción.
Y hay más. El Data Mining aplicado a los modelos financieros y bursátiles es TREMENDO. Se genera un modelo, se programa un montón de máquinas con el mismo modelo y se ponen a interactuar con la realidad… Por ejemplo, en los Mercados Continuos de Contratación, donde cientos de máquinas con programas muy similares están programadas para dar órdenes de compra o venta cuando pasen ciertas cosas. Todas igual, por cierto, con leves variaciones.
Naturalmente que, al final, el modelo se cumple: como los actores (las máquinas) actúan como si el modelo fuese la verdad inmutable, cuando hay una desviación, se lanzan las órdenes pertinentes para readecuar la desviación a la predicción del modelo… ¡Pues claro que se cumple!.
El chartismo es una chorrada de tamaño natural: “Cuando se da una figura de cabeza con doble hombro en diapasón invertido, entonces hay una inminente caída de la cotización” y cosas así que se leen en los manuales de chartismo. ¡ESO ES UNA TONTERÍA ENORME!… ¿por qué extraña razón la cotización pasada tiene que ver nada con el futuro? Y sin embargo se cumple. Claro que se cumple. Como todas las máquinas “saben” que la presencia de tal figura implica una caída, todas ellas dan órdenes de venta para “anticiparse a la caída”… y la cotización baja ¡cómo no va a bajar!. Y a ver quién se atreve a llevar la contraria a miles de máquinas pensantes que piensan todas lo mismo y además tienen billones de dólares para “jugar” en Bolsa. Además, las máquinas no se preocupan ni lo más mínimo cuando pierden monstruosas cantidades de dinero de sus dueños…
En fin.
Gracias a todos por vuestros comentarios
@Macluskey
Eres una fuente de inspiración andante… ¡Qué desparpajo! ¡Vas sobrado! ¿Cómo no nos vamos a enganchar a tus artículos?
Tu descripción de Basilea I y II es impresionante. Pensaba hablar sobre ella más adelante, pero una vez te he leído, creo que no osaré y me conformaré con referenciarte. Ya veremos.
Tu último comentario, INMENSO por cierto, entronca bastante bien con una idea que me interesaba mucho: si todos nuestros esfuerzos se concentran en rescatar un sistema subprime, ¿tendremos algo distinto a un sistema subprime barnizado? La bolsa, según la pintas, no es libre en absoluto. Si las máquinas controlan Wall Street la raza humana tiene los días contados. Perdonad la exageración.
Perdonad la exageración.
Respecto a la estadística, no sé a quién le oí decir que había que desconfiar de ella, porque si tú te comes dos pollos y yo ninguno, resulta que ambos hemos comido uno.
Otro muy buen artículo, gracias Macluskey. Curioso lo de la soja O_O
Entonces el BI + CRM + DW + Data Mining + etc … => ERP? Derivo finalmente a este sistema integrado para la “mejor” gestión y control de empresas?
Saludos.
Mazinger, el problema de la estadística es que se usa mal, como dice Macluskey.
Bien utilizada es una herramienta realmente potente y útil. Claro que la mayoría de las veces el escollo principal no es cómo analices los datos sino de dónde los sacas: el muestreo.
Cuando salen los resultados de encuestas no es ya que no te digan el intervalo de confianza o el margen de error, es que no suelen dar nunca los datos de muestreo! Y hacer un buen muestreo es muy difícil, porque tienes que representar a la población total con un puñado. De hecho, yo apostaría a que todas las veces que las encuestas fallan estrepitosamente más que porque caigan en el 5% es que estaba mal hecha la muestra.
Al fin y al cabo la muestra muchas veces no las hace el estadístico, sino un puñado de estudiantes sin pelas que se quieren sacar algo de dinerillo extra
@Mazinger: ¡¡Como no describas Basilea como dios manda, me voy a enfadar mucho!! Yo me he limitado a dar una somera pincelada para explicar por qué últimamente tanto banco ha comprado una Suite de Data Mining y ha contratado un equipo de estadísticos… ¡porque no les queda más remedio!
@Khudsa: ¿ERP? Arrgh, como buen informático, odio los ERPs. A mí me gusta diseñar y escribir sistemas de información adaptados como guantes a las empresas, que sean capaces de seguirles en su innovación, en su modelo de negocio, en su crecimiento… Un ERP es café para todos. (Un ERP típico es SAP, por ejemplo).
No me imagino yo a ninguna empresa puntera de verdad cuyo sistema de información sea un ERP. ¿Te imaginas a Google con un ERP como sistema de información? ¿A IBM? ¿A CISCO? Pues vaya. Pero eso sí: como cada vez sabemos menos, y cada vez hay menos informáticos que sepan diseñar (y no digamos programar) como dios manda, casi todas las empresas están “solucionando” sus problemas comprando ERP’s. Mi modestísima opinión es que alguna vez se arrepentirán (si existen para verlo), pero en fin. A mí me pillará jubilado, espero.
@Naeros: Qué razón tienes… qué razón! La estadística es una herramienta poderosa. Se usa fatal. Y es que además, con el temita de las encuestas electorales, hay muchísimo en juego, así que se usan las encuestas en sí como arma electoral… ¿o es que nunca os ha extrañado que diferentes medios de comunicación dén resultados totalmente dispares para predecir la misma elección? En sociología saben que mucha gente “indecisa” tiende a apuntarse al carro ganador, y vota al que se presupone que ganará las elecciones… y lo usan, vaya si usan este efecto. Que, por cierto, es el mismo que hace que el mismo tipo que ayer decía (refiriéndose al fúmbol) que “España SOMOS la mejor selección del mundo”, hoy diga que “estos de la Selección española SON unos mataos”. Seguro que conocéis a alguno de éstos…
¡Qué maravilla de discusión, civilizada, con información, sin insultos ni nada!… Qué gusto. Gracias a todos, amigos
La mención a la sociología me ha recordado una de las reivindicaciones de mi profesora: que la plantilla de INE la forman sociólogos. Viniendo de una persona que hizo la carrera de matemáticas, especializada en estadística, se comprende su chirrinta. Es como si los ingenieros intentásemos hacernos pasar por físicos, se parece pero no es lo mismo (Por si no queda claro, para unos el tema es una herramienta y para los otros un fin)
(Por si no queda claro, para unos el tema es una herramienta y para los otros un fin)
¿La moda en vez de la media? Si tuviera que elegir, yo me quedaria con la mediana, me parece, dentro de lo que cabe, la más fiable (de unas medidas tan basicas, claro)
Anda, que por lo que he leido por ahí, no pedis nada, contrastes parametricos y todo xD. El problema, es que en una presentación o les pones la media para que entiendan algo o nada, y ya sabes “el usuario no quiere que le hagan sentirse como un tonto”
Me encanta esta serie, me ha servido para aclarar muchas cosas acerca de la informática que se supone que debería conocer mejor (pero no era así). Y seguramente, entre lo que más me gusta están tus opiniones y reflexiones sobre los temas que vas tratando.
Por eso, te pido fervientemente que te olvides de hacer el “mutis por el foro” cuando acabes la serie y, por favor, nos regales más artículos sobre otros temas que vayan surgiendo y nos comentes más cosas acerca de tus experiencias y opiniones.
Bueno, y si no es así, y quieres descansar de los artículos una temporada (que espero que no), como sueles decir, difruta de la vida
Un saludo y muchísimas gracias, Carlos
@Solrac-Carlos: Me alegra profundamente que así haya sido, querido amigo.
Mi única idea era, efectivamente, conar un montón de cosas que he vivido y que, debidoi a la vida loca, pero loca, loca que llevamos, se nos han olvidado… Si lo he conseguido, como dices, estaré feliz… Ya lo estoy de hecho, con tantísimos grandes comentarios que ha habido a lo largo de toda la serie.
Y de momento, la serie debe terminar. Es lo mejor. Después de “la burbuja puntocom” que viene, tan sólo que da despedirse… pero no descarto volver a escribir sobre cualquier otra cosa más adelante, claro que no. ¡Si no me callo ni debajo del agua!!!
Gracias, y un saludo
Realmente muy revelador el comentario de que conviene guiarse por la moda en poblaciones dispersas, en vez de por la media. ¿Cuál es el salario de moda? ¿Año pasado más IPC? En ingeniería informática se me atragantó, y mucho, las asignatura de estadística. Luego comentí la imprudencia de matricularme en un master de matemáticas donde se ve mucho data mining, SAS y SPSS. Al fin y al cabo, hay que reforzar los propios puntos débiles. Notas: -Walmart, creo que se escribe con “L” simple. -Quiero ver ese artículo completo sobre Basilea I y II. -No creo que DM venga de meaning, sino de mining. Realmente es una actividad tan ardua como la minería del carbón (silicosis excluida). Aunque es cierto que hay mucho traductor tarugo. -Sobre proyectos en astronomía con DM: el más famoso y de actualidad es la búsqueda de planetas extrasolares, en que se registra la luminosidad de multitud de estrellas al ser parcialmente eclipsadas por los tránsitos planetarios.
@Alfonso: Efectibvamente, Walmart se escribe con una sola l… ylo curioso del asunto es que lo sé perfectamente, y voy y lo pongo con dos… qué chapuza, por favor!!! Gracias por el aviso, veré de corregirlo.
Sí, desde luego que Data Mining no viene de meaning… era una especie de chiste anglo-español que, por lo que veo, no tiene mucha gracia. Pero sigo pensando que lo de apalear datos y más datos a ver si encuentro el segmento adecuado no es muy gratificante; lo es comprender el significado de los datos, a l oque se llega (o no!) al final del proceso.
Y en cuanto al salario de este año, los que tengan la suerte de tenerlo, será, como mucho, =año pasado y gracias. Conozco ya casos en que les han bajado los emolumentos… claro que, a cambio, han tenido que asumir el trabajo de los dos compañeros a los que han despedido. Un chollo, vamos. También para las compañías, que así no van, tampoco, a ninguna parte. Esperemos que vuelva la cordura pronto…
Gracias por comentar.
Saludos, acabo de leer tu artículo y te comento, una de las circunstancias que pudo haber contribuido a que los gobiernos tuvieran que ayudar a los bancos en el año 2010 pudo haber sido esta desregularización de los depósitos en los bancos centrales.
http://es.wikipedia.org/wiki/Crisis_de_la_eurozona_en_2010
Felicitaciones por tus artículos son una fuente de información muy fácil de digerir, porque se habla de temas técnicos.
Geniales los artículos, Mac, “tocayo”. He descubierto esta serie hoy mismo y los estoy devorando. Enganchan como una novela buena. Yo me dedico (aún) a data warehousing y business intelligence, y durante algún tiempo tomé como cierta la anécdota de los pañales y la cerveza. Un día, hace ya 10 años, me sorprendí a mí mismo en la caja del supermercado con dos únicos artículos: ¡pañales y cerveza! Me partía de risa yo solo, y nadie de alrededor lo entendía. Enhorabuena.
Enhorabuena.
Ah, se me olvidó comentar que me gustó la “explicación” de por qué Data Mining es Mining y no Meaning. Aunque, para mí, el nombre evoca esa posibilidad de que, filtrando y filtrando datos, al final, de vez en cuando, se encuentra una pepita de oro o un diamante en bruto. Muy de vez en cuando.
Aunque, para mí, el nombre evoca esa posibilidad de que, filtrando y filtrando datos, al final, de vez en cuando, se encuentra una pepita de oro o un diamante en bruto. Muy de vez en cuando.
Caramba, tocayo… Me alegro que te guste y, sobre todo, que te haya servido para algo.
Y no veas lo que me he reído con lo de los pañales y la cerveza: me lo imagino y me parto, literalmente En fin, cosas de frikis…
En fin, cosas de frikis…
Saludos
No sabía que era tan complicado lo del data mining, mi padre lleva años utilizando el SPSS y eso que no es un lince en lo que respecta a la informática (es estomatólogo, lo utiliza para estudios estadísticos de los implantes que se ponen en la facultad)
Me temo MAC que la relacion entre el SPSS y la descarga de soja es más que dudosa, imposible en el aspecto de mineria de datos y tal vez plausible en las antiguas versiones, mas centradas en las estadististicas, de SPSS.
Pero vayamos a los datos. Ese fenomeno se da en algunos puertos y en algunas ciudades. En CARTAGENA se dio tambien. Si vemos este informe “Boletin Epidiemologico de Murcia”, http://www.murciasalud.es/recursos/ficheros/1676-BE1988-V10-N437.pdf , nos dice al principio (en un estudio sobre un brote epidémico de asma en Cartagena) que
“A raiz de las comunicaciones previas del Grup collaboratiu per lèstudi de l’asma a Barcelona sobre la posible relacion etiológica entre la descarga de grano de haba de soja y los brotes de asma observados en dicha ciudad…”
El informe se publico en Abril luego se realizó en el PRIMER TRIMESTRE DE 1988 y la comunicación del Grup de Barcelona llegaria a finales de 1987 o principios de 1988 y obviamente se realizó en 1987 o antes ¿Ya existia la mineria de datos en 1987?.
Creo que más bien se utilizó (si hubiera algo de verdad) alguna versión primitiva de SPSS para documentar un asunto de narices, literalmente. El polvo de soja desprende un tufillo (más bien peste, según te pille) característico. Solo hay que sumar dos y dos o mejor dos y tres ya que tambien habia que considerar el viento: para que se produjera brote era necesario descarga soja + viento en dirección a la ciudad.
Nota final: excelente serie y muy en vigor todavia.
{ 1 } Trackback
Historia de un Viejo Informático. El descubrimiento de la Minería… de Datos…
[…] no sólo hay que poder consultar la información y navegar por ella… Hay que encontrar las íntimas relaciones de los datos que explican muchos hechos de negocio, buscar nichos desconocidos o no explotados para abrir nuevos negocios o mejorar los exis…
Escribe un comentario