

Red Neuronal
Tras la la introducción a la Inteligencia Artificial y un vistazo a los debates filosóficos que conlleva la inteligencia artificial, hoy vamos a centrarnos en un tipo de algoritmo utilizado para “crear” IA: las redes neuronales.
En ellas, la unidad básica se denomina neurona y recibe unas entradas (valores numéricos) a las que realiza una operación (generalmente suma) y al resultado le aplica una función. Esta función devuelve otro resultado que envía a más neuronas, hasta llegar a la salida final. La idea general está inspirada en el sistema nervioso animal, siendo una pobre imitación del mismo, pero muy útil para nuestros propósitos.
Cada entrada dirigida a una neurona viene acompañada de un peso, el cual multiplica el valor de la entrada. La entrada total de la neurona será la suma (u otra operación) de todas ellas al que, en ocasiones, se le suma una constante umbral. En toda red hay dos capas conectadas con el exterior, la capa de entradas que recibe los datos, y la capa de salidas, que devuelve la respuesta de la red. Entre ambas pueden situarste una o más capas denominadas ocultas. La capa de entradas tiene la función de distribuir los datos entre la red, por lo que no se suelen contar cuando se habla del número de capas que tiene una red.
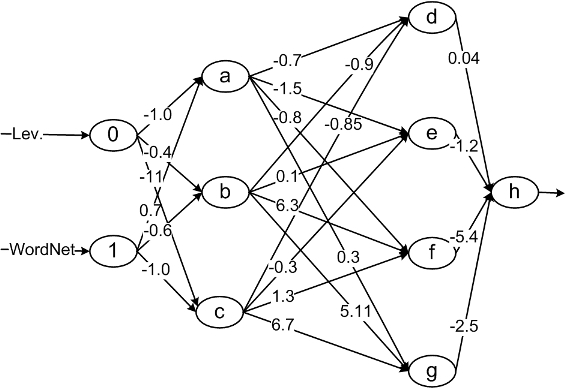
Red neuronal con pesos (extraída de)
En el ejemplo de arriba, las neuronas verdes, a la izquierda, representan la capa de entrada. Esto quiere decir que poseemos dos datos distintos (Lev y WordNet a la derecha) para la información que queremos procesar. Estos datos, tras “sufrir” unas determinadas operaciones, son enviados a las neuronas azules del centro, a cada una de las cuales no tiene porqué llegar el mismo valor, porque se multiplican por el peso asociado a cada flecha, que puede verse en la imagen derecha. Podéis apreciar como son todos completamente distintos, incluso positivos y negavitos. Finalmente, ésta capa aplicaría las funciones que le correspondan y la enviaría a la última neurona (en la imagen derecha aún envían a una capa más). La última neurona tras aplicar su función devolvería la salida final, que sería la flecha que sale de la h.
Sin embargo, ésta no es la única forma de construirlas, en estas imágenes la información sólo viaja de las capas de atrás a las de delante, lo cual no es cierto para todos los modelos. Siendo común en algunos la transmisión entre las neuronas de la misma capa o incluso hacia atrás, es decir, entre a, b, y c, o de f hasta b.
Con esta idea básica se han establecido muy diveros tipos de redes neuronales clasificados según su número de capas (monocapa, multicapa) , topología (unidireccionales, realimentadas), aprendizaje (supervisado, no supervisado, mixto), datos de entrada/salida (contínuos, discretos), tipo de respuesta(autoasociativa, heteroasociativa). Con lo que tenemos Perceptron (problemas dicotómicos, de clasificación), MLP (problemas no linearmente separables), Adaline (Perceptron con entradas reales y no binarias), Máquina de Bolzman (problemas de combinatoria), Memorias Asociativas (recuperación de información mediante alguna de sus partes, por asociación), Red de Hopfield(tipo de asociativa, basada en perceptron), Mapas autoorganizados/Redes de Kohonen y muchos otros tipos diferentes.
Las redes neuronales tienen dos fases principales de operación: aprendizaje o entrenamiento, recuerdo o ejecución. Durante el entrenamiento se aplican “ejemplos“, generalmente un conjunto de datos conocidos que definen una solución conocida, que mediante una regla de aprendizaje modifican los diferentes pesos de cada neurona en función de cómo difiera la respuesta de la red de la solución esperada. Los valores de estos pesos representan el grado de conocimiento. El entrenamiento concluye cuando el margen de error entre la salida de la red y la salida real es aceptable. Después, en la fase de ejecución, se aplican nuevos datos con solución desconocida y se espera que la red esté preparada para dar una solución verdadera en base a lo aprendido durante el entrenamiento. Generalmente en esta fase cesa el aprendizaje, por lo que no se modifican los pesos.
Estos “ejemplos” de los que hablaba no son nada especial. Pueden ser fotografías de pacientes con cáncer de pulmon y sanos (que estén catalogadas) y la red “descubrirá” patrones en ellas. Luego, se pasa una nueva foto y debería discernir si hay cáncer o no. Unos datos de entrada más comunes podrían ser edad, sexo, peso, altura, color de piel, color de ojos, color de pelo, grupo sanguíneo, y la salida la raza a la que pertenece el sujeto. O figuras geométricas, bien sea mediante imágenes o las coordenadas de sus puntos y líneas en el plano. Tamaños de hojas, de pétalos, color de flores, y altura del tallo… y catalogamos flores. Las posibilidades son infinitas.
Para terminar, veamos un ejemplo real de un proyecto de la NASA para controlar “fábricas verdes” de alimentos vegetales en el espacio. Dependiendo de la luz, temperatura, humedad relativa,CO2, nutrientes, edad, y tipo, cada planta tiene una diferente tasa de transpiración (agua que libera), allocation ¿cuota? (porcentaje comestible de biomasa) y la asimilación (índice de fotosíntesis). Representando esto en forma de red, quedaría así:
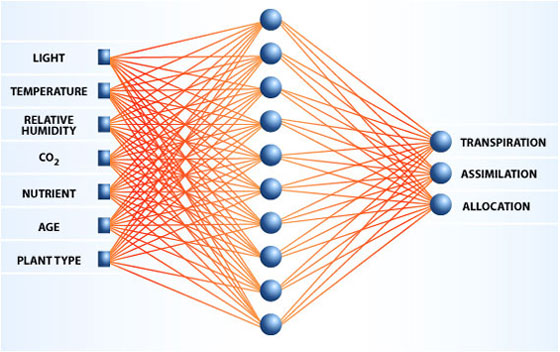
Red para control de invernadero.
Con esta información y la ayuda de las redes neuronales, los ingenieros de la NASA están desarrollando un invernadero que regule por sí mismo los diferentes parámetros (agua, temperatura, luz…) para cultivar unas plantas que desarrollen mayores porcentajes comestibles con el menor gasto de recursos posible. Esto, que ya puede parecer importante en cierta medida para cualquier agricultor terrestre, se convierte en algo crítico en una misión tripulada de varios años en la que se puede llevar lo justo.
Y hasta aquí llega la presentación de las Redes Neuronales. En el próximo capítulo me centraré en un tipo especial de las mismas, el Perceptrón, y su generalización, el Perceptrón Multicapa.

The Inteligencia Artificial: Redes Neuronales by Ender Muab'Dib, unless otherwise expressly stated, is licensed under a Creative Commons Attribution-Noncommercial-No Derivative Works 2.5 Spain License.


{ 11 } Comentarios
Buen articulo. Dos cosas, primero estaría bien que pusieras un separador, para que no se vea todo el articulo en la protada. Y en segundo lugar, cuando leeo sobre esto me biene a la cabeza la teoria del caos, de la que queria escribir un articulo. No te asustes no se trata de nada raro, en realidad es denominada dinamica no lineal y se trata de una rama de las matematicas que estudia el comportamiento de redes muy complejas que interacionan entre ellas con muchos factores y cada uno tiene un peso especifico. En realidad las redes neureonales, el clima, o los ecosistemas se rigen según las leyes de la teoria del caos (dinamica no lineal). Es interesante y me recuerda mucho a tu articulo. Solo por poner un ejemplo de un problema de dinamica no lineal. Como varia una red de 100 bombillas donde cada bombilla esta conectada a 4 bombillas de la red, si introducimos la orden apaga las bombillas de tu alrededor que esten encendidas y enciende las apagadas (suponiendo que el 50% estan encencidas i el 50% estan apagadas de forma homogenea), luego si todas estan conectadas con todas, o si la distribucion de encendidas apagadas es al azar. Esta clase de problemas me recuerdan a lo que decias de las neureonas y a tu articulo en general.
Gracias. No me acordaba del separador, como no estoy acostumbrado a utilizarlos, siempre los olvido, de hecho las otras veces fue Pedro quién los añadió. Pero ya está puesto.
Respecto a la teoría del caos, ánimo con ese artículo. Es una disciplina muy desconocida e interesante de la que querría aprender más. Supongo que sí que ha de tener mucha relación, pues que la idea de muchas redes es resolver problemas no lineales, que a nosotros nos cuesta mucho más de pensar.
No sé cómo se resolverán ahí los problemas, pero en las redes es, casi todo, pura estadística.
¡Saludos!
Muy interesante, pero me ha sabido a poco. Veamos: describes el QUÉ es lo que hace la red, explicas un poco CÓMO lo hace, y nos dejas un PORQUÉ AsÍ dE GrAnDe!
Me recuerda al último artículo de los neutralinos en los que Pedro, explicó muchas cosas para las que el PORQUÉ, era tan complejo que no lo tenía claro ni él. (supongo y espero que este no sea ahora el caso).
Por otro lado, el ejemplo que ha puesto Belerofot, me ha recordado un programa que intenté hacer para resolver sudokus, en el que cada celda tenía un estado: una lista de valores candidatos a valor de la celda, y cada celda intentaba mejorar su estado a partir del estado de las otras celdas de su fila, columna o región, y les avisaba a todas ellas cuando hacía un cambio de estado.
Buen artículo, endermuaddib.
Quizá te has dejado explicar que en lo que describes como “fase de recuerdo”, es decir, cuando la red explota el conocimiento aprendido en la fase de entrenamiento para aplicarlo a nuevos casos, lo que se hace es ejecutar un programa (módulo, subprograma, rutina, llámese como se quiera) que contiene embebidas todos los valores y algortimos detectados por la red.
En general, una vez que se considera que la red ha aprendido lo suficiente, lo que se hace es generar el código fuente de un programa (en C, Java, Assembler o en lo que sea) que contiene esta información aprendida, y que una vez compilado, es susceptible de ser llamado por el programa que captura los datos para su evaluación.
Un ejemplo puede ser la concesión de un crédito (un caso clarísimo son las autorizaciones online que se hacen de las transacciones de las tarjetas de crédito). En el caso de hacerse mediante una red neuronal (la verdad es que no conozco ningún caso en que se haga así, pero podría perfectamente hacerse), en primer lugar la red se entrena para averiguar cuándo una transacción es (o tiene toda la pinta de ser) fraudulenta (por el importe, la localización del comercio, el tipo de comercio, la hora, la senda de consumo del cliente, etc). Una vez terminado el entrenamiento, se genera un programa, que es llamado por la transacción concreta que se ejecuta al solicitar crédito. Este programa (consecuencia de la información de la red, pero que NO es la propia red), informa SÍ o NO, punto. Y como consecuencia, la operación se autoriza o deniega. Esa es má-o-meno la forma de operar para autorizar operaciones con tarjetas de crédito, sea cual sea el modelo de aprendizaje que se utilice.
Enhorabuena, sigue así. Saludos a Dune. Y a la Reina Insectora, también.
joel ¿Por qué? ¿Te refieres a las operaciones que hacen a nivel interno que cambian los pesos y dan una respuesta adecuada? Si es eso a lo que te refieres, me temo que es distinto para cada red, de modo que no podía explicarme tan a fondo en todos los casos. Tendrás que esperar al próximo artículo para ver cómo funciona el Pereceptrón Multicapa, a ver si consigo despejar algo tus incógnitas.
Macluskey, vaya, tienes toda la razón, la verdad es que releyéndolo, no he dejado muy claro que la información de la red que se va modificando durante el entrenamiento y que termina por quedarse con unos valores “correctos” es la que se guarda y se utiliza luego siempre igual cuando se pretende ejecutar la red esperando la “solución” en un caso real.
La Reina Insectora dice que ha encontrado unas grandes cuevas con enormes depósitos de agua, así que está haciendo algunas colonias en Dune.
Gracias y saludos.
Quizá he sido demasiado genérico.
El funcionamiento de la red lo explicas como hacer pasar unos valores de entrada por una serie nodos de una red. En cada nodo se aplica una función al valor de entrada, y a la salida se multiplica el valor de salida por el peso que tenga el enlace que una a este nodo con el siguiente. Así hasta que llega un valor a la salida.
En el modo de aprendizaje, se compara este resultado con el que sabemos que tendría que dar, y se ajustan los pesos de los enlaces entre nodos.
¿Correcto?
Falta saber ¿qué utilidad tiene hacer “circular” por la red los valores de entrada? y ¿qué funciones se han de utilizar?. Y sobre todo ¿de qué forma se reajustan los pesos de los enlaces?.
Supongo que como dices, hay distintos tipos de redes y cada una funciona de una manera, por lo que de forma genérica no se puede explicar más que lo que has dicho. Pues nos esperaremos al siguiente artículo.
Con respecto al modo de recuerdo, para mi no es más que, como he dicho antes, hacer circular por la red los valores de entrada, y obtener un resultado a la salida. Vale que es posible que se pueda optimizar creando un programa que a partir del estado de los pesos de los enlaces de la red, obtenga el mismo resultado que la red en un tiempo menor (como la diferencia entre un programa interpretado y otro compilado).
Y el modo de aprendizaje, es un proceso independiente que ajusta la red en función de la relación entre el resultado obtenido y el esperado. Por eso cuando se está aplicando la red a problemas nuevos, no se puede utilizar puesto que no se puede comparar el resultado, con el esperado puesto que este último se desconoce. Posteriormente cuando elementos externos a la red (personas, analistas u otras redes) evalúen el resultado se puede volver a ajustar la red, es decir: APRENDER.
Por cierto, cada vez que se reajusta la red, ¿deberían de volverse a probar TODOS los casos que antes funcionaban para ver si el reajuste ha sido beneficioso? En tal caso, la red, además de los pesos de sus enlaces, debería tener también un registro de todas las pruebas que ha hecho con el resultado que tenían antes de hacer el cambio. E incluso un historial ordenado de cambios con la relación: prueba, configuración,resultado.
Bueno eso ya será cuestión de la política que tenga el proceso de aprendizaje.
Enhorabuena. Acabo de engancharme a la serie todavía más.
Joel: Sobre tu pregunta de por qué hay que pasar casos conocidos, me voy a volver a centrar en el problema de la autorización de operaciones con tarjeta de crédito.
Problema: Hay una persona que está comprando (online) un artículo en una tienda determinada, y saca una tarjeta para pagar. El vendedor pasa la tarjeta por el datáfono, y en unos breves segundos, un chino bajito oculto en un servidor del Banco debe decidir si autoriza la operación o no. Si autoriza, el Banco carga con el riesgo, es decir, el Banco transfiere el parné a la cuenta de la tienda. Si luego el cargo a la tarjeta no se atiende (lo que se llama en “default”, o impago, porque el dueño de la tarjeta está “tieso”, o se la han mangao, o cualquier otra cosa), el Banco palma la pasta, porque al autorizar la operación ha dado su visto bueno. Pero casi es peor si se deniega una autorización a una operación legítima: el dueño de la tarjeta se cabrea y se cambia de Banco, además del lucro cesante, al no poder hacer la operación y cobrar las comisiones oportunas.
Hasta aquí está claro, supongo.
¿Qué datos tiene el Banco para autorizar o no el cargo? Pocos, en principio: el número de la tarjeta (o sea, el cliente, con su saldo, historia, etc), el importe, la tienda donde se hace la operación, fecha, hora… poco más. Aunque también tiene la Historia de lo que ha pasado a lo largo de los años. Pero debe contestar en segundos. Así que…
Para eso sirven las técnicas de Data Mining, en general, y las Redes Neuronales en particular.
El banco tiene una ENORME historia de operaciones que se han hecho a lo largo de los años. La mayoría de ellas, fueron buenas, pero algunas fueron malas. Se trata de aprender de lo que pasó (el pasado) para poder predecir el futuro. Se intenta averiguar qué hace diferente a las transacciones que fueron fallidas, cuál es el perfil del defraudor, qué tipo de uso se da a una tarjeta robada (que su propietario legítimo no hubiera hecho)… Te aseguro, joel, que esto no es una ciencia, es casi un arte. Los responsables del Comité de Crédito (que en definitiva son los humanso que asumen la responsabilidad) se mueven más por el olfato que otra cosa. Un ejemplo: una persona que nunca ha consumido fuera de España, empieza a hacer operaciones en Punta Cana. ¿Le han robado la tarjeta, o es que está, por primera vez de vacaciones? Y además está comprando joyas, cuando en España compra sobre todo ropa. ¿Es una operación fraudulenta o es legítima? Y hay que contestar en un par de segundos, además…
Así que se le envían a la Red muchas operaciones pasadas (lo más modernas posibles, pero muchas), con su resultado: Esta fué bien, esta mal, etc, y se intenta que la Red aprenda de los patrones que permiten discernir entre un pufo y una operación legítima.
El resultado, una vez obtenido, debe ser muy rápido y estable en el proceso, de ahí que se genere un programa con toda la información y se le llame en el sistema. Y como los chorizos son mu pero que mu listos, y cambian su modus operandi cada día, hay permanentemente que estar entrenando la Red para que vaya tomando nota de los nuevos sistemas de choriceo.
Espero no haberme puesto pesado, y que se haya entendido. Saludos
Viéndolo como un mecanismo para tomar una decisión rápidamente sobre algo complejo, pues sí que lo veo. Pero es algo bastante limitado. “Redes neuronales” suena a algo más…
Yo es que tenía en mente algún sistema de aprendizaje/control de algún tipo de robot autómata, que gracias a sus redes, dependiese menos de las especificaciones de su programa de control. Es decir que aparte de los casos considerados por su diseñador, estuviera preparado para casos nuevos, no contemplados anteriormente.
Bueno, creo que he visto muchas pelis… A ver que nos trae el próximo artículo. Ánimo endermuabdib
Bueno, lo que se busca no es simplemente realizar un cálculo en milésimas de segundo, eso sólo era un ejemplo de Macluskey para comprender mejor qué hacen.
Su verdadera utilidad, y donde radica su potencia, es su capacidad para resolver problemas de variables lineramente independientes. Pese a lo potente de nuestro cerebro y nuestra inherente capacidad para establecer patrones, no somos muy buenos en este ámbito. Por ejemplo, según el índice de masa corporal (altura partido peso) si pasa de 25 diremos que una persona tiene sobrepeso, y si no llega a 20 sabremos que es anoréxica. Y dependiendo de su complexión podremos afinar más su situación: alguien muy musculado podría tener un índice de masa superior a 26 y no consideraríamos que tiene sobrepeso.
En definitiva, no es muy sencillo comprobar mediante la experiencia que si dividimos la altura por el peso y nos da unos valores, asegurar un estado sobre la salud de cada individuo. Una vez sabemos esto, es trivial deducir cómo quedará un paciente modificando alguno de los parámetros (como el peso). También, una vez se ha deducido el algoritmo, es sencillo hacer un programa informático que lo calcule y nos devuelva el estado de cada paciente.
Por el contrario, hay otros problemas para los que somos unos zotes. Si los datos no tienen ninguna relación entre sí, y la variación de alguno por separado no es aparentemente significativa, nos iba a costar una burrada establecer un modelo correcto y, por ello, casi imposible escribir ningún algoritmo.
Ahí es donde entran las redes neuronales. Quien va a desarrollar el programa no sabe realmente cómo se tiene que comportar ante las distintas situaciones, así que no puede programar ningún algoritmo que lo resuelva. Lo más que puede hacer es entrenar una red neural para que aprenda a comportarse en ese caso.
Respecto al robot… bueno, supongo que se podría llegar a algo parecido asignando un montón de redes neuronales a cada acción que vaya a poder realizar, o algo parecido.
Pero ojo, no necesariamente hay que entrenar las redes con un lenguaje y ejecutarlas con otro. Macluskey simplemente lo dijo en el ejemplo porque generalmente los mejores algoritmos de entrenamiento están en entornos matemáticos que luego tendrán una difícil integración en otros sistemas. Entonces, una vez lo has entrenado con Matlab, R, o lo que sea, te interesa pasarlo a Java para incrustarlo en un applet o a C++ para que controle un brazo robótico. Pero bien podrías hacerlo todo mediante el mismo sistema.
De todos modos, las redes neuronales tienen más funciones que la clasificación en salidas dicotómicas; pero me parece que tanto Macluskey como yo conocemos mucho mejor el Perceptrón Multicapa, que es el especializado en estas tareas, y por eso todos los ejemplos van por ese camino. Pero vuelve al invernadero de la NASA y piénsalo…
¡Menudas parrafadas soltamos! Me alegro de que inciten al diálogo y la reflexión. El siguiente artículo, sobre el Perceptrón, tendrá que esperar. Entrego el proyecto la semana que viene y voy a estar bastante liadillo. Tengo el código casi cerrado, pero me queda toda la parte de la documentación, que es un coñazo y hay bastante que hacer. Como tendré que explicar un poco en qué consiste en MLP en la Memoria, haré un copipaste para ir abriendo boca.
¡Saludos!
Bueno yo he pensado, que con esto de la crisis y el poco trabajo que hay y la necesidad de dinero tan grande…si no existiera el dinero todo seria mas facil, entonces mi solución es, crear unos robot que se autoconstrulleran solos, por lo tanto solo habria que crear uno, y que hicieran todas las tareas diarias, construlleran pisos, hicieran pan, regasen los huertos….todo para que nadie tubiera que trabajar, por lo tanto todo seria gratis, el dinero no existiria y todos tendriamos de todo, y el mundo seria fantastico!!!!!
Samuel, sin animo de ofender… Mira esa ortografía. Me da bastante pena ver conceptos intelectuales expresados de manera tan pobre, sobre todo con las herramientas de corrección ortográficas que incorpora actualmente cualquier dispositivo electrónico.
Escribe un comentario